PKU GeekGame 1st 部分题目Write-Up
Hackergame结束后,我又参加了PKU举办的GeekGame,本以为在Hackergame发挥不错,可以在GeekGame混混名次。
然而参赛后感觉难度太大了,全程被大佬们按在地上摩擦,一阶段完整解出的题只有五道,只拿了1000分,总排名仅为42;二阶段随着提示的放出,基本丧失了做题兴趣,也没有再怎么拿分了。

→签到←
Hackergame的Web签到题做多了,导致拿到一个Misc的签到题有点不知所措,题目没有给任何描述,只有一个PDF文件:
用Chrome浏览器打开这个PDF文件如下所示:

似乎说后面一串奇怪的字符就是flag的样子,但我完全没办法把这些字符和flag联系起来。
研究了许久无果后,我无意间全选了一下PDF里面的内容,复制粘贴到一个空白文件中,发现了玄机:
1
fa{aeAGetTm@ekaev!
lgHv__ra_ieGeGm_1}看上去除了第一排混进来一个没什么用的”1”以外,后面两排可以组合成flag。再研究一下,发现就是个栅栏密码,交替取上下两排的字符,即可还原出flag。
flag{Have_A_Great_Time@GeekGame_v1}
说起来顺利做出这题还得感谢我平时一直用Chrome看PDF的习惯,一些使用常规PDF阅读器的选手都遇到了没办法选中超出界面的字符的问题。
小北问答Remake
查看题面
You 酱善于使用十种搜索引擎,别人不清楚的知识她能一秒钟搜索出来。这是众人皆知的事实。
You 酱的朋友菜宝在刷往年题的时候找到了一份没有答案的资料。她本想询问 You 酱,但听说 You 酱已经早在 5 月份就把课程辅导这项业务外包给了你。
于是,现在菜宝手持两枚 Flag,希望你能帮她解答这些题目。你每小时可以提交一次答案,答对至少一半可以获得第一个 Flag,全部答对可以获得第二个 Flag。
这题模仿了Hackergame的猫咪问答,但感觉难度高了不少,一共八个题,每做出四个可以拿一个flag,另外提交答案有1h的CD,直接送走了爆破选手(例如本人。题目如下:
展开题目
- 北京大学燕园校区有理科 1 号楼到理科 X 号楼,但没有理科 (X+1) 号及之后的楼。X 是?
答案格式^\d+$ - 上一届(第零届)比赛的总注册人数有多少?
答案格式^\d+$ - geekgame.pku.edu.cn 的 HTTPS 证书曾有一次忘记续期了,发生过期的时间是?
答案格式^2021-\d\d-\d\dT\d\d:\d\d:\d3\+08:00$ - 2020 年 DEFCON CTF 资格赛签到题的 flag 是?
答案格式^.+{.+}$ - 在大小为 672328094 * 386900246 的方形棋盘上放 3 枚(相同的)皇后且它们互不攻击,有几种方法?
答案格式^\d+$ - 上一届(第零届)比赛的“小北问答1202”题目会把所有选手提交的答案存到 SQLite 数据库的一个表中,这个表名叫?
答案格式^[a-z]+$ - 国际互联网由许多个自治系统(AS)组成。北京大学有一个自己的自治系统,它的编号是?
答案格式^AS\d+$ - 截止到 2021 年 6 月 1 日,完全由北京大学信息科学技术学院下属的中文名称最长的实验室叫?
答案格式^.{15,30}(实验室|中心)$
我的解题方法(其中用到的搜索引擎均为Google):
- 依次搜索”北京大学燕园校区理科X号楼”($X \in \mathbb{N}^+$),搜到$X=6$时,没搜出来相关结果,因此这题应该是5。
- 搜索”北京大学信息安全综合能力竞赛闭幕”,搜到链接,里面写了注册人数为407。
- 这题是我最后搜出来的,最开始的反应:这种信息能去哪搜啊?后来经过漫长的搜索,得知有Google有一个证书透明化的项目,打开此链接,在里面搜索”geekgame.pku.edu.cn”,拿到一堆历史证书: 注意到只有最后那个Let’s Encrypt的证书是已经过期了的(点进去一看在2021年7月11日过期),遗憾的是,报告中没有提供具体的时间,但回答这题需要精确到秒。思考片刻,我打开了浏览器开发者工具,抓了一下这个页面的包,抓到如下数据:顺利拿到日期数据的UNIX时间戳,不过这里单位是毫秒,看到秒数是3我就确信找到了正确答案,将其转成日期:
time.strftime("%Y-%m-%dT%H:%M:%S+08:00", time.localtime(1625964593))得到精确到秒的时间:2021-07-11T08:49:53+08:00。从Rank 1大佬的题解中发现crt.sh这个网站,搜起来更容易。 - 这种正规的比赛肯定会有Github仓库,直接找到然后在里面查到2020年quals签到题文件,即可发现flag:OOO{this_is_the_welcome_flag}
- 这一题最开始被我当成了算法题研究了一天,随后作罢,开始正经搜答案。这题对搜索的关键词要求挺高的,如果搜中文关键词,基本拿不到什么有用的结果,都是清一色的“八皇后”问题。而如果搜”placing 3 quees on m * n board”,则可以搜到以下文章:A047659 - OEIS,里面给了通项公式,代入m和n去算就好了,这里我用python一开始遇到了浮点数精度问题,后来用符号计算解决了问题。答案是2933523260166137923998409309647057493882806525577536。(算出这个通项的人真是又无聊又牛逼。
- 去GeekGame-0th的Github仓库查看,发现答案。submits
- 这题如果不加限制去搜,很容易搜到一个答案:AS24349,它的全称是CERNET2 IX at Peking University,但我提交了一下发现不对,后来注意到题目问的是“北京大学自己的自治系统”,搜”autonomous system number for peking university”,第一个结果是AS59201 Peking University details - IPinfo.io,得到此题真正的答案:AS59201。
- 百度百科上居然能搜到答案,拉到“学术研究”标题,可以找到一个名字很长的实验室:“区域光纤通信网与新型光通信系统国家重点实验室”。
 注意到只有最后那个Let’s Encrypt的证书是已经过期了的(点进去一看在2021年7月11日过期),遗憾的是,报告中没有提供具体的时间,但回答这题需要精确到秒。思考片刻,我打开了浏览器开发者工具,抓了一下这个页面的包,抓到如下数据:
注意到只有最后那个Let’s Encrypt的证书是已经过期了的(点进去一看在2021年7月11日过期),遗憾的是,报告中没有提供具体的时间,但回答这题需要精确到秒。思考片刻,我打开了浏览器开发者工具,抓了一下这个页面的包,抓到如下数据: 顺利拿到日期数据的UNIX时间戳,不过这里单位是毫秒,看到秒数是3我就确信找到了正确答案,将其转成日期:
顺利拿到日期数据的UNIX时间戳,不过这里单位是毫秒,看到秒数是3我就确信找到了正确答案,将其转成日期:
翻车的谜语人
查看题面
作为曾担任上届比赛命题工作的资深谜语人,You 酱这次也被邀请来出一道考察信息隐写的 Misc 题目。You 酱找组委会确认了本届劳务费能否准时发放后就迅速开工了,但她不知道,这其实是一个彻彻底底的陷阱。
事实上,组委会曾在几个月前收到了报告,称 You 酱或违反规定在题目里私自掺杂大量私货,但这只是个猜想,不一定对。于是,组委会在邀请 You 酱命题的同时,派出间谍麻里奈小姐持续关注 You 酱的一举一动,希望能够发现决定性的证据。
麻里奈小姐不负众望,通过量子波动算法截获了一段 You 酱访问境外服务器的流量记录。现在她想让你来帮忙分析其中的端倪。
这是一个流量分析题,我还是第一次接触这类题,之前也几乎没用过Wireshark。
拿到数据,发现是个pacp文件,用Wireshark打开:
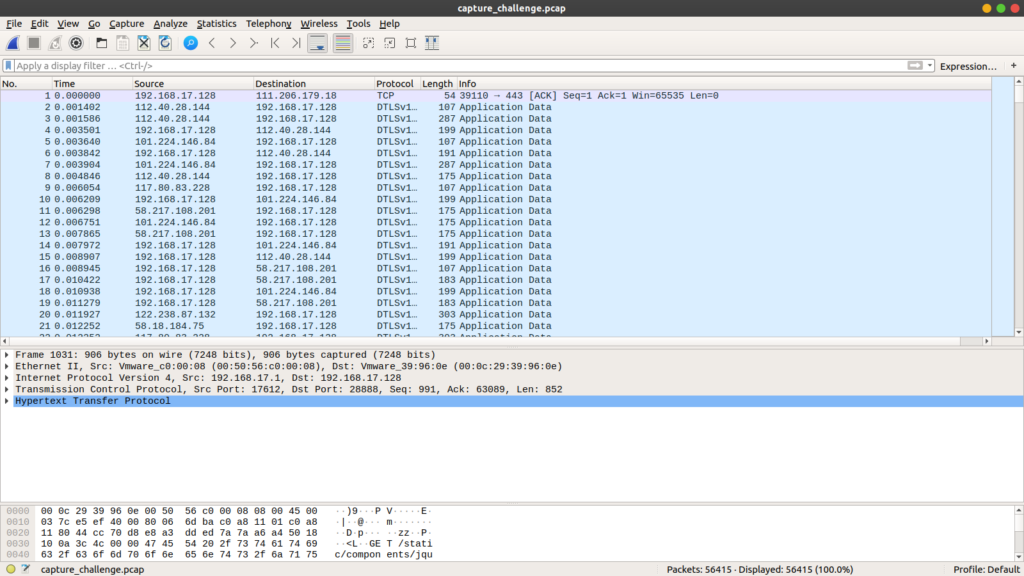
先简单看了看流量的来源和目的,发现有两个内网IP:192.168.17.1、192.168.17.128,另外还有诸多公网IP,目测公网IP没什么用,先过滤掉:ip.src == 192.168.17.1
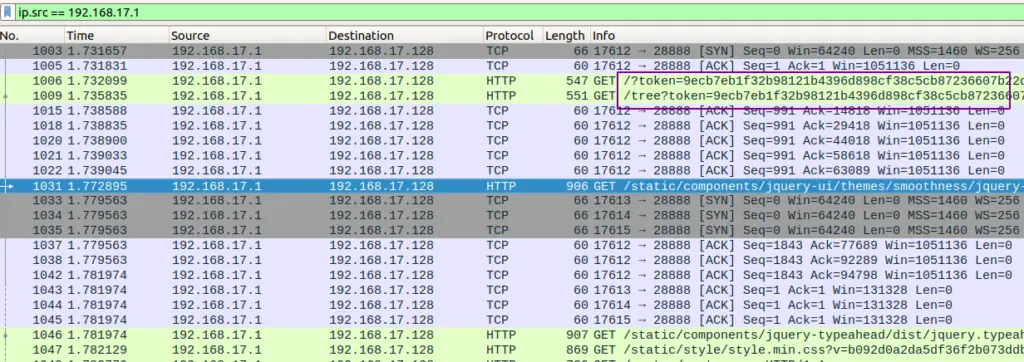
注意到图中圈出的两条流量,经常用Jupyter notebook的同学应该对这两个链接不会陌生,看来You酱应该在和服务器上的Jupyter notebook进行交互,估计flag就藏在其中。
但这里的数据包实在是太多了,也不太好一个一个找,因此直接搜索hex值为”666c6167”(flag)的内容,马上就找到了相关信息。
从Jupyter notebook给的数据包中可以拼凑出其中的代码:
from Crypto.Random import get_random_bytes
import binascii
def genflag():
return 'flag{%s}'%binascii.hexlify(get_random_bytes(16)).decode()
def xor_each(k, b):
assert len(k)==len(b)
out = []
for i in range(len(b)):
out.append(b[i]^k[i])
return bytes(out)
flag1 = genflag()
flag2 = genflag()
key = get_random_bytes(len(flag1))
encoded_flag1 = xor_each(key, flag1.encode())
encoded_flag2 = xor_each(key, flag2.encode())
with open('flag1.txt', 'wb') as f:
f.write(binascii.hexlify(encoded_flag1))
with open('flag2.txt', 'wb') as f:
f.write(binascii.hexlify(encoded_flag2))同时还可以找到其中key的值:
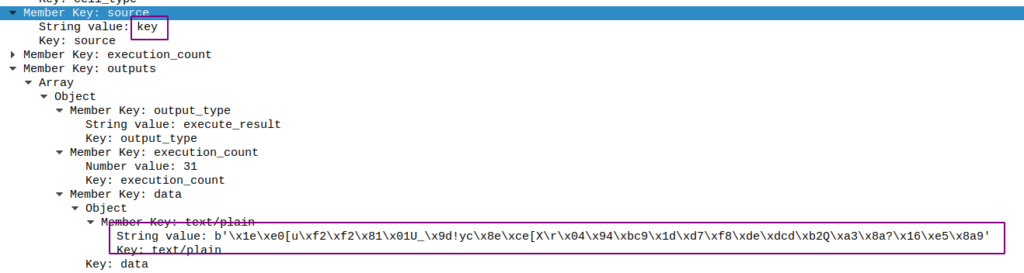
如此一来,只要能获取flag1.txt和flag2.txt,就可以通过以下代码解出两个flag(这里我直接把结果写在里面了,后面再说flag密文的获取方法):
import binascii
key = b'\x1e\xe0[u\xf2\xf2\x81\x01U_\x9d!yc\x8e\xce[X\r\x04\x94\xbc9\x1d\xd7\xf8\xde\xdcd\xb2Q\xa3\x8a?\x16\xe5\x8a9'
### flag1
encoded_flag1 = '788c3a1289cbe5383466f9184b07edac6a6b3b37f78e0f7ce79bece502d63091ef5b7087bc44'
encoded_bytes = binascii.unhexlify(encoded_flag1)
flag1 = []
for i in range(38):
flag1.append(encoded_bytes[i] ^ key[i])
print(bytes(flag1))
### flag2
encoded_flag2 = '788c3a128994e765373cfc171c00edfb3f603b67f68b087eb69cb8b8508135c5b90920d1b344'
encoded_bytes = binascii.unhexlify(encoded_flag2)
flag2 = []
for i in range(38):
flag2.append(encoded_bytes[i] ^ key[i])
print(bytes(flag2))Flag1
点击Wireshark左上角File->Export Objects->HTTP,打开一个通过HTTP传输的文件列表,仔细寻找,发现两条flag相关文件:
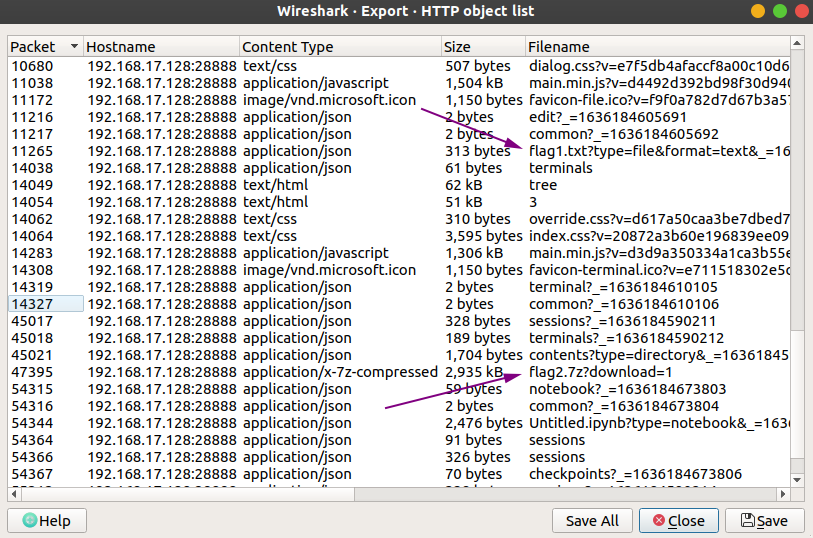
把他俩导出。其中flag1.txt内容如下:
{"name": "flag1.txt", "path": "flag1.txt", "last_modified": "2021-11-06T07:43:20.952991Z", "created": "2021-11-06T07:43:20.952991Z", "content": "788c3a1289cbe5383466f9184b07edac6a6b3b37f78e0f7ce79bece502d63091ef5b7087bc44", "format": "text", "mimetype": "text/plain", "size": 76, "writable": true, "type": "file"}于是我们拿到了flag1。
Flag2
flag2是一个7z压缩文件,解压发现需要密码。思路中止了感觉应该还有相关信息,因此继续分析流量。在刚才的流量中继续翻,发现还有Websocket流量,随便看了几条比较靠前的,发现拼凑起来是个”pip3 install”,意识到与服务器有Shell交互,可能会有压缩文件之类的操作,因此筛选出来自192.168.17.128的websocket流量:websocket and ip.src == 192.168.17.128
由于操作Wireshark不熟练,后面websocket内容我都是一个包一个包地看过去,并把内容拼起来,拼起来之后发现You酱敲的命令大概长下面这样:
pip3 install stego-lsb
stegolsb wavsteg -h -i ki-ringtrain.wav -s flag2.txt -o flag2.wav -n 1
7za a flag2.7z flag2.wav -p"Wakarimasu! `date` `uname -nom` `nproc`"因此解flag2化为解date、uname -nom和nproc这三条命令在压缩时的输出字符串。
date命令首先需要知道执行命令的具体时间,好在Wireshark记录了每一个package的相对时间,翻到最开始的websocket流量,可以找到一条登录信息,其中含有登录时间的字段:
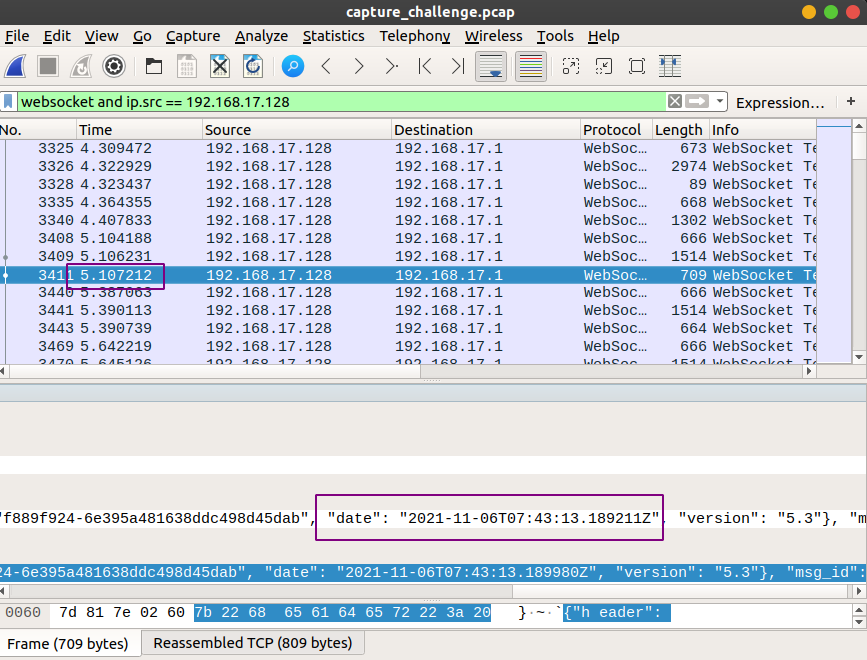
记录下wireshark内的时间戳和对应的date字段,然后就可以算出敲下压缩命令时的时间应该是”2021-11-06T07:44:15Z”,不过注意到这个时间以Z结尾,是UTC时间,服务器上显示的时间应该是CST,这是由于:
我发现flag2.wav的生成时间比上面那个正好多了8个小时,所以date命令敲下的时刻应该是”2021-11-06 15:44:15 CST”,现在只需要关心date命令的输出格式即可,而这个格式一般和系统有关。经过寻找,我发现You酱的服务器是kali linux:
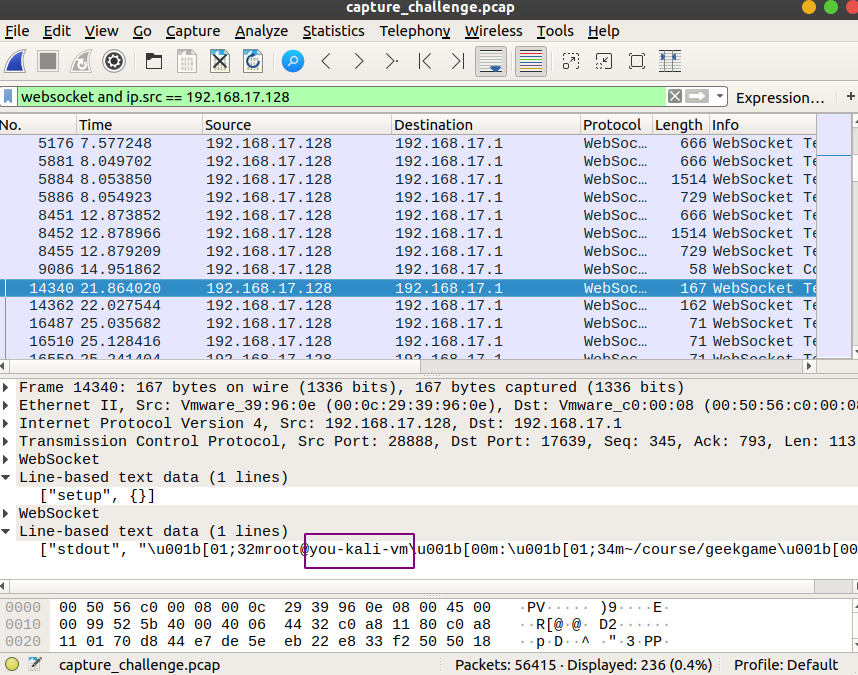
这里顺便把uname命令的输出解决了(you-kali-vm x86_64 GNU/Linux)。
正好电脑上有一个kali的docker容器,打开来跑了一下date,得出前面date命令的输出为:Sat 06 Nov 2021 03:44:15 PM CST。
另外,nproc命令的默认输出一般是CPU核心数量,在7za命令的输出结果中,可以找到下面的内容:
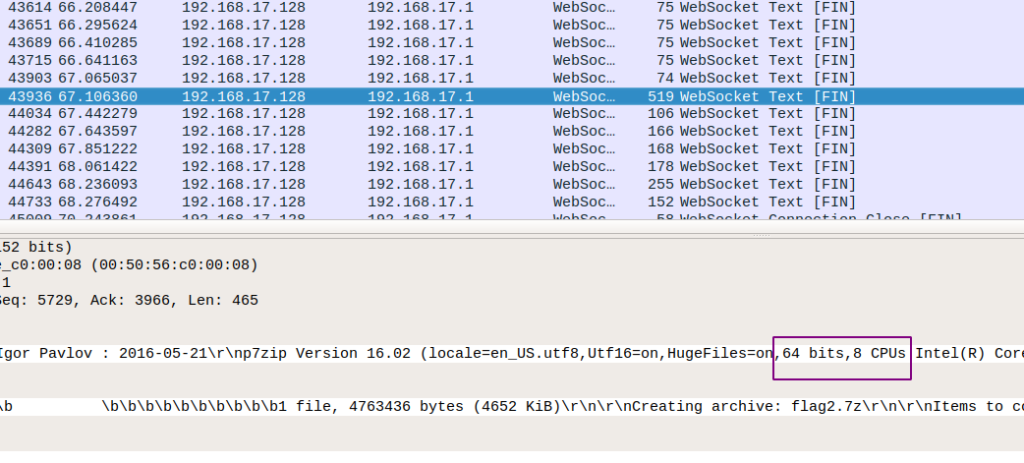
64bit说明前面uname的输出x86_64应该是对的,8 CPUs说明nproc很可能就是8。
试了一下密码:Wakarimasu! Sat 06 Nov 2021 03:44:15 PM CST you-kali-vm x86_64 GNU/Linux 8
成功解压出flag2.wav,接下来用stego-lsb进行decode,可以获取到加密后的flag2:
stegolsb wavsteg -r -i flag2.wav -o flag2.txt -n 1 -b 76最后用最开始的代码解一下密,flag2也获取到了。
- flag1: flag{9d9a9d92dcb1363c26a0c29fda2edfb6}
- flag2: flag{ffdbca6ecc5d86cb71cadfd43df36649}
在线解压网站
查看题面
Q 小网盘可以在线预览多种文件,但是唯独压缩文件不能在线解压。这让小 A 十分难受。
为了解决这个问题,小 A 写了一个在线解压网站。只要你上传zip文件到这个网站,它就会自动帮你解压,之后你就可以访问解压出来的文件了。配合着浏览器插件,可以完美解决 Q 小网盘的痛点。
为了让大家相信他的网站是安全的,不会把压缩文件内容的泄漏给其他人,他在磁盘根目录下放了一个叫 flag 的文件,声称只要能拿到其中内容就可以获得一顿火锅。你以他的网站功能并不完整为理由,想骗取一顿火锅。然而他只是表示这并不影响网站的安全性,只有攻破网站的人才能获得火锅。
你十分生气,铁了心地要吃上这顿免费的火锅。
你可以下载本题的程序
一开始随便上传了一个文件,然后尝试了直接访问/media/../../../../flag之类的路径,但用浏览器访问拿到404,用requests访问拿到400,均行不通。后来发现,后端代码是用open函数把文件读出来返回给我的,那么应该可以通过sym link去拿flag文件。因此:
sudo ln -s /flag hello压缩为hello.zip并上传,下载hello文件打开即获取flag。
flag{NEV3r_truSt_Any_C0mpresSed_File}
密码学实践
查看题面
小 R 在秋季学期选了一门叫《密码学基础》的课程。然而在第一节课上,他就发现这门课似乎和他想象中的不太一样(懂的都懂)。
望着投影上密密麻麻的数学公式,中期退课的意愿在他的脑中愈加强烈。他只是想学一下密码学在现实中的应用,怎么就变成了数学公式的推导了呢?
他还记得第一节课的课件上的一句话:“学了这门课后,你也不能学会设计一个密码学系统”。
但他仍在这门课上了解了不少知识。他了解了哈希函数的构造,了解了私钥密码系统的设计,了解了现有的公钥密码体系。
“既然课程只讲密码学理论,那我就自己做密码学实践。”
这是他构建的密码学世界,他希望在这个世界内只有对的人才能拥有旗帜。
同样是密码学类型的题,这题也比Hackergame 2021的Easy RSA难的多,与前者相比,后者只能算是一个简单的数学题了。不过由于我并没有学过密码学,因此第二问中RSA签名的伪造方法相比于大佬的解法复杂了不少。
这题有两个flag,拿到代码先看一下两个flag在哪给出,容易找到它们都位于server.py的doRichard函数中:
def doRichard():
print(MESenc(pad(("Hello, Alice! I will give you two flags. The first is: "+flag1(token)).encode("utf-8")),Public_key).hex())
print(MESenc(pad(("Sorry, I forget to verify your identity. Please give me your certificate.").encode("utf-8")),Public_key).hex())
Acert=int(input().strip())
sinfo=dec(Acert)
akey=unpackmess(sinfo)
pinfo=sinfo[:len(sinfo)-len(akey)-2]
aname=unpackmess(pinfo)
if aname!=b"Alice":
print("Who are you?!")
return
old_key=int.from_bytes(Public_key,'big')
comm_key=pow(int.from_bytes(akey,'big'),int.from_bytes(Richard_key,'big'),P)
for i in range(128*8):
if (comm_key>>i)&1:
old_key=(old_key^(old_key<<(i+1)))%(2**2048)
new_key=int.to_bytes(old_key,256,'big')
print(MESenc(pad(("I can give you the second flag now. It is: "+flag2(token)).encode("utf-8")),new_key).hex())
return通过选择”Talk to Richard”可以执行这个函数,但不幸的是,Richard发来的消息均经过了加密,加密算法位于rsa.py,如下:
def MESenc(mess:bytes,skey:bytes):
assert len(skey)==8*32
keys = [bytes_to_long(skey[i*8:(i+1)*8]) for i in range(32)]
assert len(mess)%32 == 0
cip=b""
for it in range(0,len(mess),32):
pmess=mess[it:it+32]
a = bytes_to_long(pmess[0:8])
b = bytes_to_long(pmess[8:16])
c = bytes_to_long(pmess[16:24])
d = bytes_to_long(pmess[24:32])
for key in keys:
a, b, c, d = b, c, d, a ^ c ^ key
a=long_to_bytes(a,8)
b=long_to_bytes(b,8)
c=long_to_bytes(c,8)
d=long_to_bytes(d,8)
cip+=a+b+c+d
return cip用到的密钥是一个随机生成的长度为256 byte的Publik_key,并且没有告诉我们。但有一个突破口是,我们拥有一条已知密文的明文:
“Sorry, I forget to verify your identity. Please give me your certificate.”
看看能不能通过这个信息解出同样由Public_key加密的带有flag1的明文信息。
Flag1
带着这个想法我开始研究MESenc函数,我发现它的加密算法是将pad后的消息按长度每32分为一组,每一组再拆成4个长度为8的子串,然后对每一组分别进行一轮独立的加密,加密的过程是将密钥分为32个长度为8 byte的子密钥,然后进行一轮看似简单的迭代:
for key in keys:
a, b, c, d = b, c, d, a ^ c ^ key虽然迭代过程很容易懂,但通过明密文推出key是不太现实的事。但我们发现,这里唯一出现的运算是异或($\oplus$),而异或有一些很好的性质:
- $x\oplus y = y \oplus x$
- $x\oplus x = 0$
- $0\oplus x = x$
对于每一组的a、b、c、d,若把加密之前的值记为$a_0,b_0,c_0,d_0$,加密之后的值(密文与之对应的分组)记为$a_1,b_1,c_1,d_1$,那么$a_1,b_1,c_1,d_1$一定都是由$a_0,b_0,c_0,d_0$以及所有的子密钥按某种未知但固定的组合进行异或运算得到的。
按此逻辑,如果我们有两条由同一密钥加密得来的长度相同的密文,它们的分组数量因此相同,分别取它们来自同一位置分组(比如都取出各自的第0组)的$a,b,c,d$值,记为$a_1,b_1,c_1,d_1$和$a_2,b_2,c_2,d_2$,分别进行异或运算:
结合异或运算的三条性质,上面的操作可以把所有与密钥相关的变量消去。因此得到的四个异或值与密钥是没有关系的,只与明文有关系。而很巧的是,这里Richard发来的两条密文的长度都是96,这样就不会有落单的分组了。
在这种情况成立的条件下,我们只要看一下经过32轮迭代以后的$a,b,c,d$除掉与key相关的值以后,与迭代前的$a,b,c,d$的具体映射关系,可以画一个表格看一下$a,b,c,d$每一轮的变化:
| a | b | c | d |
|---|---|---|---|
| b | c | d | a ^ c |
| c | d | a ^ c | b ^ d |
| d | a ^ c | b ^ d | a |
| a ^ c | b ^ d | a | b |
| b ^ d | a | b | c |
| a | b | c | d |
| … | … | … | … |
我们发现,它具有周期6,而32 % 6 = 2,故32轮迭代后,最终的(去掉所有key相关的值以后)结果应该是:
- $a_1=c$
- $b_1=d$
- $c_1=a\oplus c$
- $d_1=b\oplus d$
所以可以推导出这样一个结论:
已有明文$m_1$与$m_2$,使用同一密钥进行加密得到的密文分别是$cip_1$与$cip_2$,则任取两条明文的同一位置上的分组$a_1,b_1,c_1,d_1$和$a_2,b_2,c_2,d_2$以及两条密文对应的分组$a_3,b_3,c_3,d_3$和$a_4,b_4,c_4,d_4$,则必定满足:
- $c_1\oplus c_2 = a_3\oplus a_4$
- $d_1\oplus d_2 = b_3\oplus b_4$
- $a_1\oplus a_2\oplus c_1\oplus c_2 = c_3\oplus c_4$
- $b_1\oplus b_2\oplus d_1\oplus d_2 = d_3\oplus d_4$
因此,我们可以写出解密代码如下:
from Crypto.Util.number import bytes_to_long, long_to_bytes
import binascii
def pad(msg):
n = 32 - len(msg) % 32
return msg + bytes([n]) * n
def group(msg):
results = []
for it in range(0, len(msg), 32):
pmsg = msg[it: it + 32]
a = bytes_to_long(pmsg[:8])
b = bytes_to_long(pmsg[8: 16])
c = bytes_to_long(pmsg[16: 24])
d = bytes_to_long(pmsg[24: 32])
results.append((a, b, c, d))
return results
def get_xor(cip1, cip2):
r1 = group(cip1)
r2 = group(cip2)
result = []
for (a1, b1, c1, d1), (a2, b2, c2, d2) in zip(r1, r2):
result.append((a1 ^ a2, b1 ^ b2, c1 ^ c2, d1 ^ d2))
return result
def get_message(msg1, xor_result):
r = group(msg1)
result = []
for (a, b, c, d), (ra, rb, rc, rd) in zip(r, xor_result):
result_c = c ^ ra
result_d = d ^ rb
result_a = rc ^ a ^ c ^ result_c
result_b = rd ^ b ^ d ^ result_d
result.append((result_a, result_b, result_c, result_d))
msg2 = b''
for a, b, c, d in result:
a = long_to_bytes(a, 8)
b = long_to_bytes(b, 8)
c = long_to_bytes(c, 8)
d = long_to_bytes(d, 8)
msg2 += a + b + c + d
return msg2
def decode(cip1, cip2, msg2):
"""To decode cip1"""
cip1 = binascii.unhexlify(cip1)
cip2 = binascii.unhexlify(cip2)
msg2 = pad(msg2.encode("utf-8"))
msg1 = get_message(msg2, get_xor(cip1, cip2))
return msg1以我拿到的两串密文为例,解密flag1,只需:
flag1_cip = '8981fe27b7ab28561cb53c4ec48f74c4d2cc4a3e3ecd15096f31c35057f3bbb28d9cb222e4f6614615f4225af7ca31e0f1940c3b63db0f762a4dd64465f0dec4a189fc14d89b075d719d4d29b9a708bbc6e4683e70b44e345e02ba0d659ebd89'
cip = '8a87b23df2be284600b53c4ec4dd20dacac0183a6dd815113f3ecf4711e4d2ac9981e42eb7a1240000fa305391cc65c1eecc522f389f40303f47c04d42e386b7e9ff855c80db56376e825236a6b817a48ebe3b4005f03f4c5f78d95a03f386e5'
msg = 'Sorry, I forget to verify your identity. Please give me your certificate.'
print(decode(flag1_cip, cip, msg).decode())Hello, Alice! I will give you two flags. The first is: flag{Fe1StEL_NeTw0rk_ne3d_an_OWF}\x08\x08\x08\x08\x08\x08\x08\x08
Flag2
接下来看看flag2的生成过程,在给出flag1后,Richard表示需要先验证我的身份,需要我输入一串十进制整数,并经过以下的操作:
Acert=int(input().strip())
sinfo=dec(Acert)
akey=unpackmess(sinfo)
pinfo=sinfo[:len(sinfo)-len(akey)-2]
aname=unpackmess(pinfo)
if aname!=b"Alice":
print("Who are you?!")
return若结果不是b"Alice",则Richard翻脸,不给我flag2。
冒充Alice
那我们只要凑一个Acert,让它的验签结果恰好是b"Alice"就可以了。
在此之前,我们需要清楚地知道验签过程中出现的dec、unpackmess函数以及他俩的逆函数enc、packmess具体在干啥,dec和enc不用多说,一看就知道,分别是RSA的解密和加密,不过这里因为是作为签名使用,加密过程用的是私钥,解密过程用的则是公钥。
另外还有两个函数packmess和unpackmess,具体如下:
def packmess(mess):
assert len(mess)<=65535
return mess+(len(mess).to_bytes(2,'big'))
def unpackmess(mess):
rlen=int.from_bytes(mess[-2:],'big')
if rlen>len(mess)-2:
mess=b'\x00'*(rlen-len(mess)+2)+mess
return mess[-(2+rlen):-2]容易知道packmess的作用是把消息长度(不大于65535)转化成2个byte并附加在消息最后,unpackmess则基本与之相反,当mess的最后两个字节表示的长度比消息自身大的时候,在消息最前面用\x00进行填补再去掉末尾两个字节;否则返回的是mess[-(2 + rlen) : -2],我们发现这个函数返回的字节长度恰好是rlen,其实说白了就是按最后两个byte给的长度来填补或截取mess再返回。
知道了这俩函数的用途后,我们首先可以得到pinfo=b'Alice\x00\x05',接下来需要推导出sinfo的值,我们重新写出两者的关系:
akey=unpackmess(sinfo)
pinfo=sinfo[:len(sinfo)-len(akey)-2]通过对unpackmess函数的理解我们可以写出一种满足条件的sinfo的值:
sinfo = pinfo + b'\x00' * rlen + int.to_bytes(rlen, 2, 'big') # 0 <= rlen <= 65535在得到了sinfo后,我们还需要计算出Acert,后者经过dec解密得到前者:
sinfo = dec(Acert)那么对应地,我们有:
Acert = enc(sinfo)现在的问题是,我们并没有拿到God的RSA密钥d,没有办法自己加密,但注意到,God那边可以注册登记人口:
def doGod():
print("My RSA N is: "+str(rsa_key[0]))
print("My RSA e is: "+str(rsa_key[1]))
print("What is your name?")
name=bytes.fromhex(input().strip())
print("What is your key?")
key=bytes.fromhex(input().strip())
if name in certs:
print("I can not issue multiple certificates to one person.")
return
if len(certs)>=5:
print("I can not remember more than 5 people.")
return
result=register(name,key)
print("Your certificate is:")
print(result)输入name和key之后,God会调用register函数生成一个certificate并告诉我们,而register函数调用了getcert函数,后者代码如下:
def getcert(name,key):
rmess=packmess(name)+packmess(key)
return enc(rmess)这里调用了enc函数,因此我们可以想办法利用一下God,让他帮我们做enc操作。
第一个想法:我们只需要构造name和key使得packmess(name) + packmess(key) == sinfo
回看前面得到的sinfo:
sinfo = pinfo + b'\x00' * rlen + int.to_bytes(rlen, 2, 'big')sinfo的前七个字节一定是b"Alice\x00\x05",这就要求packmess(name)前七个字节也是b"Alice\x00\x05",但注意到sinfo的长度是9 + rlen,如果name不是b"Alice",那么name一定是b"Alice"加上一些字节这种形式,那么packmess(name)的长度将大于7,虽然我们可以通过修改sinfo中间的pad值以让前面部分与packmess(name)相同,但事实上,在这种情况下,packmess(key)的长度将小于2 + rlen(因为二者之和是固定的9 + rlen),而packmess(key)的最后两个字节必须与sinfo一样,也是int.to_bytes(rlen, 2, 'big'),这意味着key的长度必须是rlen,这与packmess(key)的长度小于2 + rlen是矛盾的。如果name是b"Alice",那么God会把我们拦下来,因为Alice这个ID已经被抢注了。因此这条路没办法走通。
第二个想法:我们可以找一个方法来间接算出enc(sinfo)。
整理一下,目前我们拥有God提供的n和e,需要加密的信息sinfo,除此以外,一无所有。但我们仍然有办法用未知的私钥d给sinfo加密。
方便起见,下面将sinfo记为整数$m$。
我们要计算$m ^ d \ mod \ n$。
首先,找一个和$n$互素的正整数$k$,这应该比较容易。
然后计算
再令
其中最后一步应用了Euler’s Theorem。因此我们有:
上面的$k ^ {-1}$指$k$在$\mathbb{Z}_n$乘法群中的逆元,由于$k$与$n$互素,逆元必存在。
整个过程用人话讲就是说,我们随便找一个$k$,只要运气不太差就能保证$k$与$n$互素,然后计算一下$y$,让God对$y$进行加密,拿到密文$z$,最后计算$z$与$k$逆元在模$n$意义下的乘积,即拿到我们需要的$m$的密文。
接下来,唯一的任务就是根据$y$来构造name和key,使得int.from_bytes(packmess(name) + packmess(key), 'big') == y
猥琐起见,我们固定$k=2$,($n$不会有因子2吧,不会吧不会吧!),计算$y$:
k = 2
y = (int.from_bytes(sinfo, 'big') * pow(k, 65537, n)) % n设length = int.from_bytes(y.to_bytes(256, 'big')[-2:], 'big'),我们要让len(key) == length,这样在packmess之后才能与y的末两位相同,这里的256是我找的一个刚好可以覆盖y长度的值,事实上取大一点并不会影响末两位的值,这样一来,packmess(key)的长度为length + 2,至于key的值,只要从y转成的字节中取至倒数第三位,再对前面部分根据name的情况做一些修改。现在来看name,假如这里name长度不为0,那么packmess(name)会得到一些非b'\x00'的不可控量拼接在前面,由于y几乎是随机生成的,这些字节不能保证正好出现在y的对应位置上,但如果我们直接令name = b'',那么packmess(name)的值为b'\x00\x00',而这种东西,我们想要多少就可以有多少,只要把y转字节的时候故意加长一点就好了!
这样构造时,由于packmess(name) + packmess(key)的长度为length + 4,我们要把y转化成等长的字节,那么只要length + 4 >= 258 (比256多2是为了在最前面pad出至少两个b'\x00')就可以保证成功。要让随机的16位2进制数不小于254,粗略计算了一下这个概率应该不小于0.998(前9位全是0的情况下才可能小于254)。生成key的代码如下:
k = 2
def get_key(n):
y = (int.from_bytes(sinfo, 'big') * pow(k, 65537, n)) % n
length = int.from_bytes(y.to_bytes(256, 'big')[-2:], 'big')
y = y.to_bytes(length + 4, 'big')
x = y[2:-2]
return x代码的逻辑是,y.to_bytes(length + 4, 'big')的前两位有极大概率是b'\x00\x00',这部分用packmess(b'')去填补,y的中间部分y[2: -2]用key去填补,而这部分的长度是length + 4 - 4 = length,恰好是y的末两字节,因此在packmess以后恰好能把y的末两字节填上。
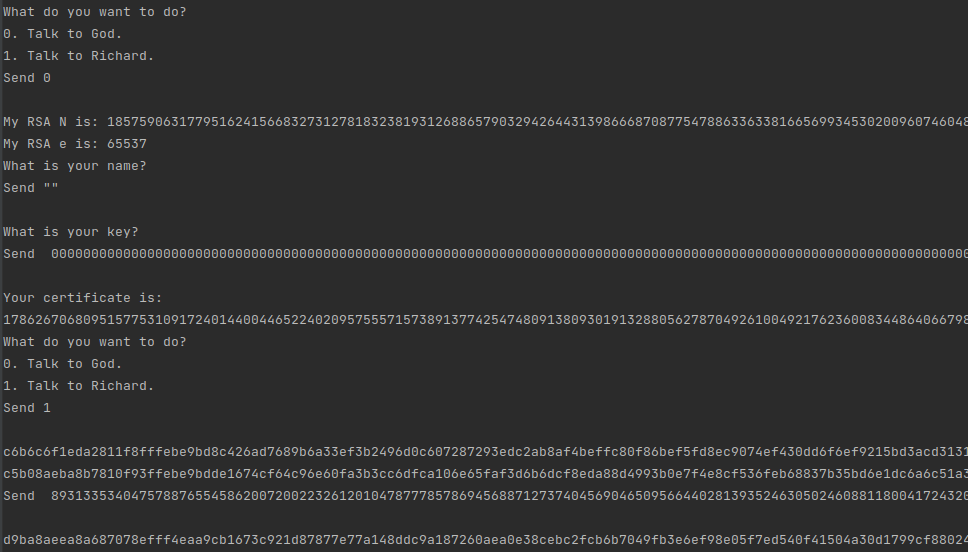
构造了name和key,我们拿去丢给God,让他帮我们加密出一个certificate出来,当然,他以为这是certificate,但实际上我们准备利用这个东西去冒充Alice:
按照前面的推导,我们已经拿到了$z$,那么计算$m ^ d \ mod \ n$只需要计算$(z \times k ^ {-1}) \ mod \ n$:
def get_certificate(n, z):
p = (z * gmpy2.invert(k, n)) % n
return int(p)这个函数用来计算我们真正需要的certificate,用以冒充Alice。
经过实验,冒充成功:
解密flag2
现在我们冒充Alice成功拿到了包含flag2的密文,但这里和前面不同的是,加密用的密钥变了:
old_key = int.from_bytes(Public_key, 'big')
comm_key = pow(int.from_bytes(akey, 'big'), int.from_bytes(Richard_key, 'big'), P)
for i in range(128 * 8):
if (comm_key >> i) & 1:
old_key = (old_key ^ (old_key << (i + 1))) % (2 ** 2048)
new_key = int.to_bytes(old_key, 256, 'big')
print(MESenc(pad(("I can give you the second flag now. It is: flag2{this_is_flag_2}").encode("utf-8")),new_key).hex())Public_key经过了复杂的计算得到了最终的new_key,如果就这么让他修改密钥,那前面用来解flag1的方法就一点用都没有了,而且修改密钥的过程还用了我们所不知道的Richard_key,重新分析新的解密方法基本上行不通。但是我们注意到,comm_key是由akey做幂运算得来的,而akey = unpackmess(sinfo)
回顾一下sinfo:
sinfo = pinfo + b'\x00' * rlen + int.to_bytes(rlen, 2, 'big')如果让rlen取为0,则akey直接变成空字节,其对应的整数是0,这样comm_key就变成0了,下面循环里的if语句一次都进不去,这样得到的new_key其实还是Public_key,如此一来,按照前面拿flag1的方法即可拿到flag2。
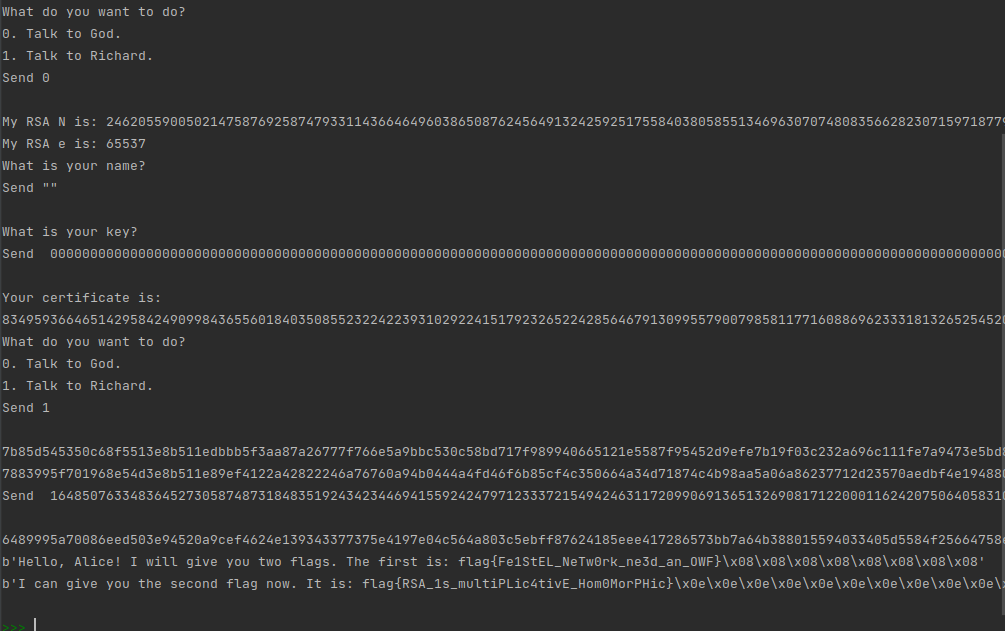
- flag1: flag{Fe1StEL_NeTw0rk_ne3d_an_OWF}
- flag2: flag{RSA_1s_multiPLic4tivE_Hom0MorPHic}
全部解题代码:
interact.py
import pwn
from pass_identity import get_key, get_certificate
from decode_flag import decode
def unpackmess(mess):
rlen = int.from_bytes(mess[-2:], 'big')
if rlen > len(mess) - 2:
mess = b'\x00' * (rlen - len(mess) + 2) + mess
return mess[-(2 + rlen):-2]
r = pwn.remote('prob08.geekgame.pku.edu.cn', 10008)
r.recvuntil(b'Please input your token:\n')
r.sendline(b'0:this_is_my_token')
print(r.recvuntil(b'Talk to Richard.\n').decode().strip())
r.sendline(b'0')
print('Send 0\n')
msg = r.recvuntil(b'What is your name?\n').decode().strip()
print(msg)
r.sendline(b'')
print('Send ""\n')
n = int(msg.split('\n')[0].split(' ')[4])
key = get_key(n)
print(r.recvuntil(b'What is your key?\n').decode().strip())
r.sendline(key.hex().encode())
print('Send ', key.hex(), '\n')
msg = r.recvuntil(b'Talk to Richard.\n').decode().strip()
print(msg)
z = int(msg.split('\n')[1])
r.sendline(b'1')
print('Send 1\n')
msg = r.recvrepeat(timeout=1).decode().strip()
print(msg)
flag1_cip, cip = msg.split('\n')
cert = get_certificate(n, z)
r.sendline(str(cert).encode())
print('Send ', cert, '\n')
msg = r.recvuntil(b'Talk to Richard.\n').decode().strip()
flag2_cip = msg.split('\n')[0]
print(flag2_cip)
msg = 'Sorry, I forget to verify your identity. Please give me your certificate.'
print(decode(flag1_cip, cip, msg).decode())
print(decode(flag2_cip, cip, msg).decode())
r.close()decode_flag.py
from Crypto.Util.number import bytes_to_long, long_to_bytes
import binascii
def pad(msg):
n = 32 - len(msg) % 32
return msg + bytes([n]) * n
def group(msg):
results = []
for it in range(0, len(msg), 32):
pmsg = msg[it: it + 32]
a = bytes_to_long(pmsg[:8])
b = bytes_to_long(pmsg[8: 16])
c = bytes_to_long(pmsg[16: 24])
d = bytes_to_long(pmsg[24: 32])
results.append((a, b, c, d))
return results
def get_xor(cip1, cip2):
r1 = group(cip1)
r2 = group(cip2)
result = []
for (a1, b1, c1, d1), (a2, b2, c2, d2) in zip(r1, r2):
result.append((a1 ^ a2, b1 ^ b2, c1 ^ c2, d1 ^ d2))
return result
def get_message(msg1, xor_result):
r = group(msg1)
result = []
for (a, b, c, d), (ra, rb, rc, rd) in zip(r, xor_result):
result_c = c ^ ra
result_d = d ^ rb
result_a = rc ^ a ^ c ^ result_c
result_b = rd ^ b ^ d ^ result_d
result.append((result_a, result_b, result_c, result_d))
msg2 = b''
for a, b, c, d in result:
a = long_to_bytes(a, 8)
b = long_to_bytes(b, 8)
c = long_to_bytes(c, 8)
d = long_to_bytes(d, 8)
msg2 += a + b + c + d
return msg2
def decode(cip1, cip2, msg2):
"""To decode cip1"""
cip1 = binascii.unhexlify(cip1)
cip2 = binascii.unhexlify(cip2)
msg2 = pad(msg2.encode("utf-8"))
msg1 = get_message(msg2, get_xor(cip1, cip2))
return msg1
pass_identity.py
import gmpy2
def packmess(mess):
assert len(mess) <= 65535
return mess + (len(mess).to_bytes(2, 'big'))
aname = b'Alice'
pinfo = packmess(aname)
rlen = 0
sinfo = pinfo + b'\x00' * rlen + int.to_bytes(rlen, 2, 'big')
k = 2
def get_key(n):
y = (int.from_bytes(sinfo, 'big') * pow(k, 65537, n)) % n
length = int.from_bytes(y.to_bytes(256, 'big')[-2:], 'big')
y = y.to_bytes(length + 4, 'big')
x = y[2:-2]
return x
def get_certificate(n, z):
p = (z * gmpy2.invert(k, n)) % n
return int(p)
总结吐槽
第一: GeekGame太硬核了,好像和主办方说的“让没有相关经验的新生和具有一定专业基础的学生都能享受比赛”不太相符,我虽不是信安出身,但也玩了三届Hackergame,三届的校内排名分别是24、15和4,按理也不算纯小白,但GeekGame的很多题给我的感受就是需要拼命猜出题人的意图,猜了半天最后发现方向错了的感觉很糟糕。个人感觉还是Hackergame的题面信息更有方向感,在解题过程中更容易定向地学到相关知识。换句话说,GeekGame的大部分题更适合经验丰富的CTF老手,而不适合纯萌新。
不过,大部分题虽然难,但看题解还是能学到很多东西的,“叶子的新歌”是个例外,这题不仅疯狂套娃,writeup给的解题过程也是没什么逻辑关联性,感觉像是凭空想出来的,我都已经把马里奥游戏跑起来了,仍没有拿到一个flag,看了这题的题解后,我除了惊叹于“这信息居然都有用?”或者“这是人能想到的?也没个提示信息”之外,别无其他想法,而且名为新歌但解题过程与音频没有任何关系,换句话说把歌换成任何其他东西也能出此题,感觉应该是出题者为了让大家欣赏他写的歌特意放进去的,显得有点生硬,我曾一直以为音频里至少会藏有一个flag,研究了很久却毫无结果。另外如rank 1大佬所说的,题目里出现了几个外部链接,这是一种不太合理的设计。(不过这题的主线故事倒是写的挺感人的)
第二: 主办方在第二阶段给的一些提示感觉不是很合理,有的提示相当于直接把题解按在了脸上,例如“翻车的谜语人”:
第二阶段提示
Flag 1. You 酱在一边挂着 B 站直播间一边使用 Jupyter Notebook 出题,你只需关心后者
Flag 2. You 酱前几天在服务器上运行了命令 date,并把输出分享给了你:Sat 06 Nov 2021 11:45:14 PM CST
感觉把第二条提示改成“You酱平时喜欢用Kali Linux系统”更合适一些,认真做过此题的选手应该都能感受到,这提示基本就差直接把flag打在屏幕上了。从给了提示以后解出此题的人数翻了一倍多也可以看出提示的不合理性。
而有的提示感觉就是说了跟没说一样,例如“诡异的网关”:
第二阶段提示
账号密码保存在哪里?
建议体会一下早在题目刚放出的时候就找到了帐号密码的保存位置但研究了几天没有结果最后拿到这样一条提示的我的心情。
这一题我最初的思路是使用pywin32接口写脚本获取文本框内容,在失败以后经过尝试找到了保存账号密码的文件,然后就一直苦于破解文件的加密(试了一堆古典密码都没成功),拿到这条提示更是让我在第二种思路的错误道路上越走越远。(虽然提示的本意可能是让我们去内存中看,不过感觉还是有一定的误导性)
这题给了提示之后解出人数只增加了8个,相比于一阶段的近50人解出,基本可以认为提示确实一点用都没有(一阶段时解出这题的人数就基本在以每天十个的速度上涨,然而给了提示之后,上涨速度反而还变慢了XD)

赛后看了别人的题解,发现这道题用WinSpy可以秒出答案(我一开始试过用pywin32写脚本获取文本框内容,然后失败了,所以思路是对的只是工具没找对咯hhh,另外这和Binary有什么关系??)
另外还有疯狂套娃题“叶子的新歌”:
第二阶段提示
使用某些软件可以查看 MP3 的 metadata
【FAQ:常用工具】里的虚拟化软件在这道题里真的有用
解题过程中得到的文本中可能包含提示
这种提示同样对卡在后几层的选手没有任何帮助。
鉴于提示没有办法照顾到所有选手,提示的质量也不易控制,我认为不如直接去掉第二阶段,再把题目出的更明确一些,减少选手们的瞎摸索时间,或许更加合理。
第三: 感觉作为一场普通的校内线上个人赛,组委会给的奖金确实有点多(至少对于大部分学生党来说,两三千块钱算是一笔不小的收入了),高额的奖金固然有利于激发选手的动力,但线上赛的本质就已经决定了没有办法从根源上杜绝作弊现象,组委会的反作弊手段再高明都不如降低奖金来的靠谱。作为对比,Hackergame中没有设置高额的奖金,只设有鼓励性质的奖品,在这种情况下选手们相对而言会更愿意为了解出flag的成就感、学到更多信息安全的知识而去解题,屯flag的卷王基本很少见(当然这符合规则,只是我认为“卷”未必是一种好的氛围),为了拿低金额的奖品而选择作弊更是没什么意思。(外校人员,奖金什么的与我无关,纯理性吐槽)
不过话说回来,体验不好的原罪还是因为自己菜,我等菜狗还需努力!
- V me 50!
- Alipay is also ok~




