手搓神经网络系列之——卷积运算的正向传播(一)
在传统图像处理中,卷积占据了非常大的比重,在Transformer出来之前,卷积神经网络(CNN)也长期霸榜CV领域的深度学习任务。
而虽然现在有Transformer等利器,但卷积神经网络仍是众多场景任务中的一把手,尚未有被取代的迹象。
本系列全部代码见下面仓库:

如有算法或实现方式上的问题,请各位大佬轻喷+指正!
为啥要单独讲卷积
以下,就是卷积神经网络的示意图:
…不好意思放错了,下面这个才是:
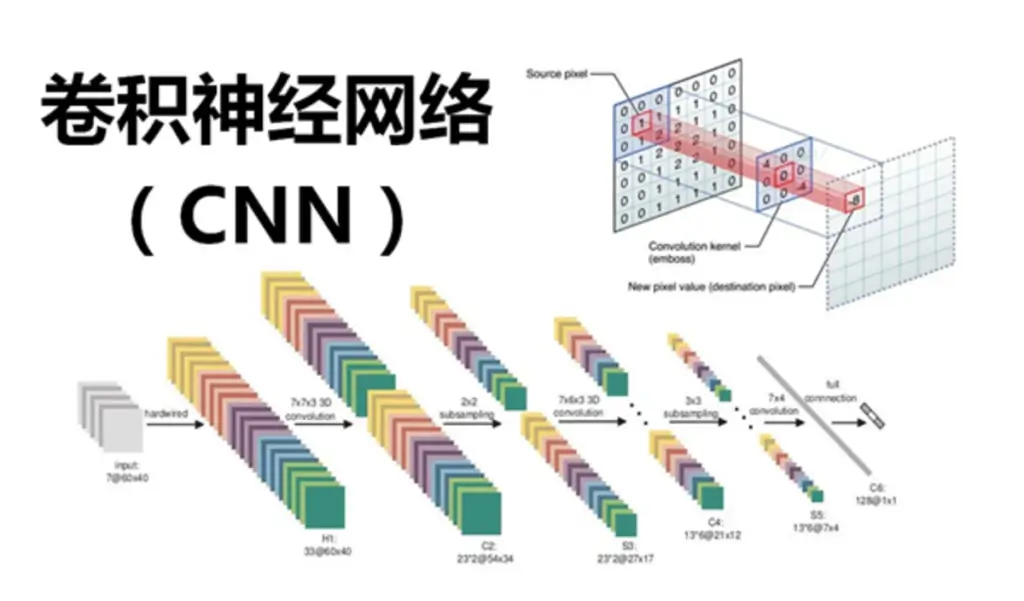
卷积运算因为其不同于其他张量运算的规则以及其重要程度,被我单独拎出来讲,还有一个原因是,卷积虽然不难理解,但其反向传播很容易掉脑细胞。不过,卷积的正反向传播都有一些trick,使用了trick后,算对只是基本操作了,还能让卷积和反向传播的速度非常的快(使用trick后的卷积运算已经和CPU版的PyTorch的卷积运行效率相近了)。
卷积运算也是需要花大篇幅讲解正向传播过程的一个运算。为了避免一步到位导致的脑细胞快速死亡,我们仍然从最基本的卷积写法开始展开,觉得自己牛逼的一批的同学可以直接进入卷积正向传播的第二篇文章。
卷积的过程,因为过于易懂,本文不再放图,大概就是有一个被称为卷积核的块,从左上到右下对整个图进行滑动遍历,在遍历的过程中,依次计算卷积核与对应块的内积,放到卷积结果的对应位置上。
算了还是放个动图以示诚意吧。
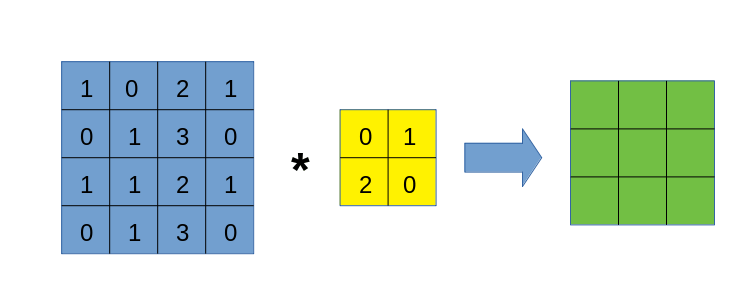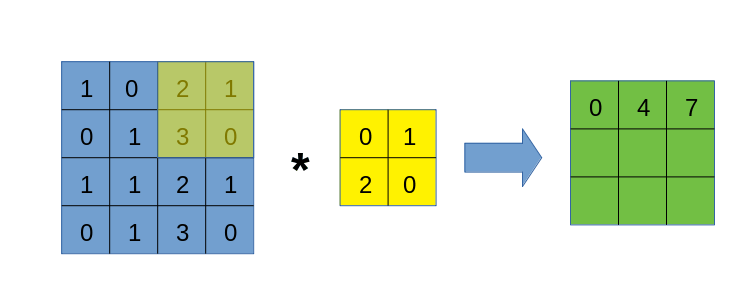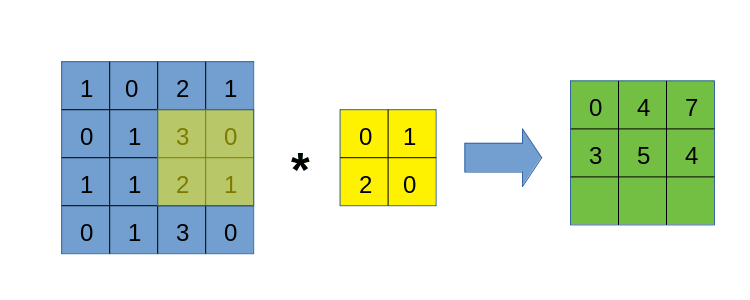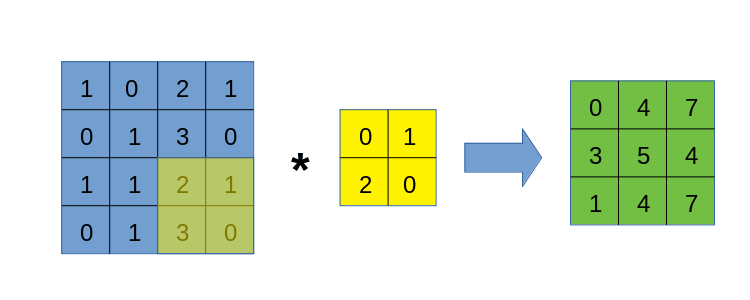
由于卷积运算带有明显的循环过程,导致我们在手写卷积时,最直接的想法就是做循环。没错,本文将先使用for循环来写卷积,目的是先熟悉卷积的过程,这样才能在后面的各种骚操作中游刃有余。
与大部分图片展示的卷积不同,在实际应用中,所谓的二维卷积其作用对象往往不止二个维度(我们只讨论对图片数据的卷积,而不考虑对序列数据的卷积,即所谓的一维卷积,事实上一维的卷积可以转化成二维的一种特殊形式来解决),我们知道普通的图片分为RGB三个通道,这会导致图片数据一般都是三维的,因此一般卷积神经网络的输入维度除了长宽两个维度外,还多了一个通道维度,另外,各卷积层的输出通常也有多个通道,所以我们通常说的卷积,卷积对象的维度至少也是3维。另外,在神经网络训练过程中,我们经常要把多个数据同时输入神经网络,这意味着数据又会多出来一个维度,直奔四维,这个概念在活在三维世界中的地球人的脑子里已经是想象不出来了,我们只能通过数学上的一些计算来推导卷积过程的性质。
卷积结果的形状
首先我们要对卷积运算中各张量的形状非常熟悉,在我的表述习惯里,被卷积张量的形状定义为(B, C, H, W),四个维度,这四个字母分别表示
- B:Batchsize
- C:Channels
- H:Height
- W:Width
Batchsize意为同时塞入神经网络的一批数据的数据量,Channels表示通道数。这个顺序和Pytorch里面的顺序是一致的,但Tensorflow等框架似乎更习惯于把Channel维度置于最后,即(B, H, W, C),不同顺序各有各的好处,建议视自己的思考习惯而定。
为了清晰起见,我们先考虑一个图片数据进入卷积层的过程,图片的形状是(C, H, W),对于卷积神经网络的卷积层而言,因为其需要捕捉图片的不同特征,故一般卷积层会有好几个卷积核,每一个卷积核将分别与输入的图片进行卷积。这里卷积核和图片一样,虽然图上画出来是二维,但实际上却有“厚度”,卷积核的“厚度”应该与输入图片的“通道数”一致,故也称为卷积核的通道数。
对于每一个卷积核,其在图片上循环移动的过程都将输出一张特征图,这特征图是实实在在的二维矩阵,不具有通道维度。多个卷积核将输出多张二维的特征图,将所有特征图在第三个维度堆叠起来,我们仍然会得到一张具有通道概念的三维特征图。这个三维的特征图,即是卷积层对一张图片的输出。
现在考虑一堆数据(B个)同时进入卷积层的情况,这时,由上面的解释,对每一个输入的数据,卷积过程都会生成一张三维的特征图,那么将多个数据的特征图继续在第四个维度上堆叠起来,我们就会得到一个四维张量,这也是卷积层真正的输出!和输入一样,是四维的,而且形状仍然可以表示为(B, C, H, W),不过输出的B、C、H、W分别变成了多少,这就需要从数学上进行计算了。
为了讨论这个问题,我们假设输入的数据形状为(B0, C0, H0, W0),卷积核共有C个,每个卷积核的形状为(C0, h, w),卷积步长为S,输出的形状为(B1, C1, H1, W1)。
由上面描述的过程,易知B1=B0,即输入多少个数据,输出就有多少个数据,并且,输出数据的通道数应该相当于卷积核的数量(因为每个卷积核会生成一张特征图,最后的输出是将所有特征图叠起来),因此C1=C。
接下来就是H1和W1的计算了,这部分的计算其实与平面上做卷积没有区别,我们可以列出不等式:
$W1、H1$为满足不等式的最大整数解,可以算出
卷积的简单实现
接下来我们就可以通过for循环来写卷积的正向传播了,首先通过输入数据的形状,计算出输出数据的形状,并初始化输出数据为零张量。
然后遍历B0个数据以及C个卷积核,再依次遍历输出矩阵的长和宽,每一次遍历时,从输入张量中找出卷积作用域,与当前遍历到的卷积核进行点积运算,得到的结果塞到输出张量的对应位置。
随便写了一下代码,如下所示:
import numpy as np
B = 2 # batchsize
C_in = 3 # channels_in
C_out = 5 # channels_out
H = 4 # Height of image
W = 5 # Width of image
kh = kw = 2 # kernel size
stride = 1 # stride for convolution
data = np.random.rand(B, C_in, H, W) # 随机生成被卷积的数据
kernels = np.random.rand(C_out, C_in, kh, kw) # 随机生成C_out个卷积核,写在一个张量里
# 计算卷积结果的长宽
H_out = (H - kh) // stride + 1
W_out = (W - kw) // stride + 1
# 初始化输出结果
output = np.zeros(shape=(B, C_out, H_out, W_out))
# 愚蠢的四重for循环
for b in range(B):
for c in range(C_out):
kernel = kernels[c]
for h in range(H_out):
for w in range(W_out):
data_field = data[b, :, h * stride: h * stride + kh, w * stride: w * stride + kw]
output[b, c, h, w] = (data_field * kernel).sum()四重for循环显得格外刺眼,但不得不说这段代码的可读性非常强!有利于我们充分掌握卷积的过程。
需要注意的是,实际写代码时,我们也会将多个卷积核在第四个维度上堆叠起来,所以代码中的kernels是一个四维的张量。因此,一般的卷积过程实际上是四维张量卷积四维张量。
以上,就是卷积运算的通俗写法,当然我感觉这个写法不利于写反向传播,同时for循环多了几层,运行效率低下。虽然上面代码仍可以进行优化,但我认为没有这个必要,通过for循环来写的卷积再怎么优化也没办法从根本上突破。我只是为了说明卷积的过程而临时用for循环写了一下。
接下来一篇文章将进入卷积正向传播的第一种骚操作,也是一种比较容易想到的操作——img2col。
- V me 50!
- Alipay is also ok~