大语言模型训练原理与实践(零):预训练
前言(吐槽)
自从大语言模型横空出世,各行业的从业者都仿佛开了挂似的,科研、工作效率那是咔咔上涨,唯独我这个正儿八经的AI在读博士生,现在却感觉自己成了个小丑🤡:眼睁睁看着LLM在世界舞台上风生水起,自己训练的人工智能模型一个个都跟人工智障似的,别说去现实环境投入使用了,连外行审稿人都忽悠不过去;至于这💩上雕花的缝合怪科研,也是憋不出个屁黔驴技穷了。最绝望的是,当我试图投身LLM的怀抱时,不好意思,显存都不够训练个demo。
在有点腻了这种闭门造车的行为以后,吐槽归吐槽,作为一个实干型的炼丹师,光把大模型用于应用、推理是远远不够的,还得弄明白它的训练原理。毕竟,只有了解了这些,才不至于在调参和部署中沦为“黑箱”工具的操作者,也意味着能更有针对性地优化数据处理流程、设计更有效的模型结构。换句话说,搞清楚训练原理,是从“用大模型”到“造大模型”的分水岭。
既然如此,接下来就该跳出“只会用API”的舒适区,真正去了解一下大模型训练过程中的三块核心拼图:预训练、SFT、RLHF 。
在开始之前,先叠几层甲:
由于笔者没有充足的算力去支持具有实用价值的大模型的训练、微调工作,本系列文章只是尽我所理解写了点最基本的大模型训练方法和逻辑,不包含任何的训练trick——这些训练技巧往往依赖大量实践经验和工程调优,在没有真实大规模实验条件的情况下难以深入探讨。
本系列文章仅讨论最传统的大模型训练流程,不涉及各种新兴的技术分支,对于更前沿或更复杂的训练范式,往往需要丰富的工程实践经验和大量实验积累才能真正掌握,故在此不作展开。
本文就先从大模型训练的第一步开始:预训练。
Transformer & GPT
Transformer
大语言模型的基本组成模块,是2017年于论文Attention is All You Need中提出的模型:Transformer。这里插句题外话:虽然我的研究方向和大模型是一毛钱关系没有,但我所使用的模型结构也包含了Transformer模块,而且我还在五年前手搓过一个Transformer,故对这个玩意我是再熟悉不过了。

因此,关于 Transformer 的基本结构我不再赘述。这里默认读者已经具备一定的相关基础,或者至少了解 Transformer 核心组件如嵌入层(Embedding)、自注意力(Self-Attention)、多头注意力(Multi-Head Attention)与前馈网络(Feed-Forward Network)。
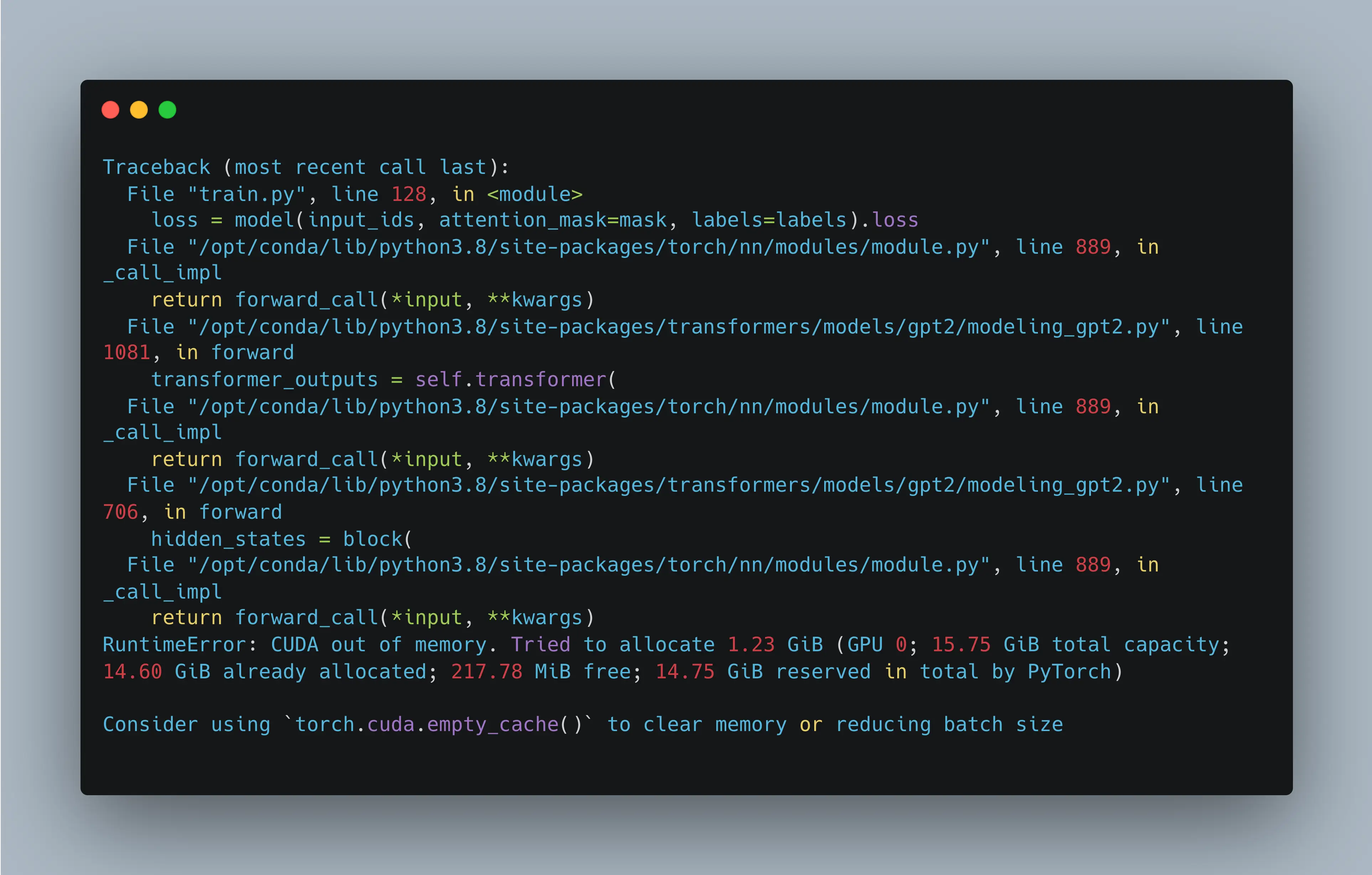
简而言之,Transformer做了一件事:使用全局注意力机制替代了传统的 RNN,实现了并行化的序列建模。而它所能达到的效果其实非常简单,仅仅是将序列整体往后预测了一个时间步:
而对Transformer模型进行训练的过程,其实也如出一辙:对一个input序列计算得到predict序列,然后将predict序列与真实的target序列进行一个Cross Entropy的计算,例如上图的例子,如果predict得到:cat is lying on the chair,则会在最后一个词上产生一个较大的分类loss。这种建模方式称为自回归建模。
以上,就是Transformer最基本的训练方法。当然,训练形式也有多种改版,例如曾经名噪一时的BERT模型,是通过随机挖去句子中的某些token,让模型对这些挖掉的token进行预测的方式来训练(做完形填空是吧?),这种建模方式则称为掩码建模。
GPT
GPT(Generative Pretrained Transformer)则是一种典型的自回归语言模型,它的基本组件正是前面介绍的Transformer——不过在设计上有一些简化与调整:
- 去掉了Encoder层,只保留了Decoder层。
- 在训练时引入了因果掩码,这是由于自回归语言模型的任务是预测下一个token,确保模型在每个位置只能访问当前位置token及之前的token,否则无异于标签泄露。
整个GPT模型则是由一堆这样的Transformer Decoder模块层层堆叠而成,通过深层堆叠来增强模型的记忆、理解与生成能力。
GPT模型的最后输出层,与前面提到的Transformer相同,同样是一个全连接线性层,用于将每个位置的隐藏状态映射到等同于词表大小的 logits 上,然后再通过 softmax 得到每个 token 的预测概率分布。同样的,这个概率分布既可用于计算Cross Entropy,又可用于在推理过程中计算下一个token。
GPT模型的预训练
随机初始化一个GPT模型的权重,我们得到了一个只会阿巴阿巴输出乱码的人工智障,它完全不懂人类的语言。为了让这个模型逐渐“开窍”,像鹦鹉学舌一样模仿人类说话,我们首先需要让它接受足够多的人类语言文本,从中学习到语言的基本结构、规律等。
这个过程,就是大语言模型训练的第一步:预训练。
那么,预训练到底在让模型学些什么?其实这个任务非常简单,正如前文提到的,模型只不过在不停地学习如何预测下一个token。
在看似简单的任务中,模型能学到的远比你感觉到的多:
除了基本的句法结构以外,它还需要掌握词与词之间的搭配规律(比如“大海捞针”比“海底捞针”更符合语言习惯,即使它们的语法都是对的);理解上下文的逻辑关系,判断当前句子下一个最合理的词是什么。在很多时候,它还需要学会一些知识——比如在输入句子:「全民制作人们大家好,我是练习时长」时,模型若想答对,就得知道接下来三个字是“两年半”。

那么模型从哪里能学到这些东西?
数据来源 & 处理
互联网时代最不缺的就是自然语言语料数据,只要愿意抓取,网页、论坛、百科、书籍、社交媒体、问答网站等等,文本信息可不要太多,而且对于这样一个预测下一个token的任务而言,这些语料数据天然自带标签,也就是说,只要把海量文本收集起来,模型就能开始进行预训练。但在此之前,仍需要对数据进行一定的预处理,包括但不限定于以下:
- 清洗无关内容:例如去除网页文本中夹带的 HTML 标签,过滤掉乱码等明显非自然语言内容。
- 优先采用高质量语料库:例如使用语言结构清晰、表达规范的维基百科等公开书面语料,这些内容能帮助模型学习到标准的句法结构和书面表达习惯。甚至还可以用传统方法训练一个分类器对文本质量进行打分,从而筛选高质量的语料。
以上,便是 GPT 模型预训练阶段的基本流程与核心逻辑。从预测下一个 token这一任务出发进行预训练,模型能够逐步建立起对语言的初步理解能力。这一阶段虽然看似简单,却是大语言模型能力构建的根基。
不过在前文中,我们略过了一个关键细节:出现了好多次的所谓 “token”,到底是什么?
在本文的例子中,它被简单描述为了某个词,但在工程上,它并不是简单的字、词,甚至有时只是一部分词。为了让模型既能处理常见词,也能灵活应对生僻词与多语言输入,我们必须对文本进行一种合理的编码与切分。这便引出了 BPE(Byte Pair Encoding)算法:一种高效的子词级编码方案,也是 GPT 等主流大模型采用的分词策略。
笔者将在下一篇文章中简单介绍 BPE 的原理与实现,看看 GPT 是如何将原始文本处理成模型输入层能够接受的 token 序列。
 V me 50!
V me 50!- Alipay is also ok~


