MCP服务编写实践
AI摘要Kimi Chat
动机
前文曾提到可以使用MCPM管理各种现成的MCP服务以使得大语言模型接入许多现成工具,那么自然会想要自己写一个适合自身需求的工具来让大模型调用,本文就来简单记录一下这个过程。
关于MCP服务的编写,GitHub上已经有了现成的仓库了:
引用站外地址,不保证站点的可用性和安全性

modelcontextprotocol
GitHub
作为一名练习时长两个两年半的Python练习生,我选择了其中的Python SDK。
配置环境
这个Python SDK支持的Python版本为:>=3.10,并且最好使用uv管理环境。
因此先安装uv:
curl -LsSf https://astral.sh/uv/install.sh | shuv安装完成后,初始化项目目录:
uv init mcp_server该操作会生成一些配置文件,以及一个虚拟环境,检查.python-version以及pyproject.toml里面Python的版本,需要>=3.10,如不满足则手动修改,然后运行uv venv,即可重置环境。
接下来安装这个SDK:
uv add "mcp[cli]"编写代码
这里,我们让LLM来做一件简单的事:列出我桌面上的所有文件
编写main.py:
import os
from mcp.server.fastmcp import FastMCP
mcp = FastMCP('windshadow-universe')
@mcp.tool()
async def list_desktop_files():
"""列出桌面上的文件"""
return os.listdir(os.path.expanduser('~/Desktop'))
配置Claude Desktop
在Claude Desktop的配置文件(claude_desktop_config.json)中添加一项:
{
"mcpServers": {
...
"windshadow-universe": {
"command": "/absolute/path/to/uv",
"args": [
"run",
"--project",
"/absolute/path/to/project/dir/mcp_server",
"mcp",
"run",
"/absolute/path/to/project/dir/mcp_server/main.py"
]
}
}
}这里有三个绝对路径需要替换,分别是uv的绝对路径、通过uv初始化生成的项目目录mcp_server的绝对路径,以及前面创建的main.py文件的绝对路径。如使用相对路径则会失败(
接下来打开Claude Desktop,并让它列出我的桌面文件,Claude会作出回应调用我们刚刚写的函数:
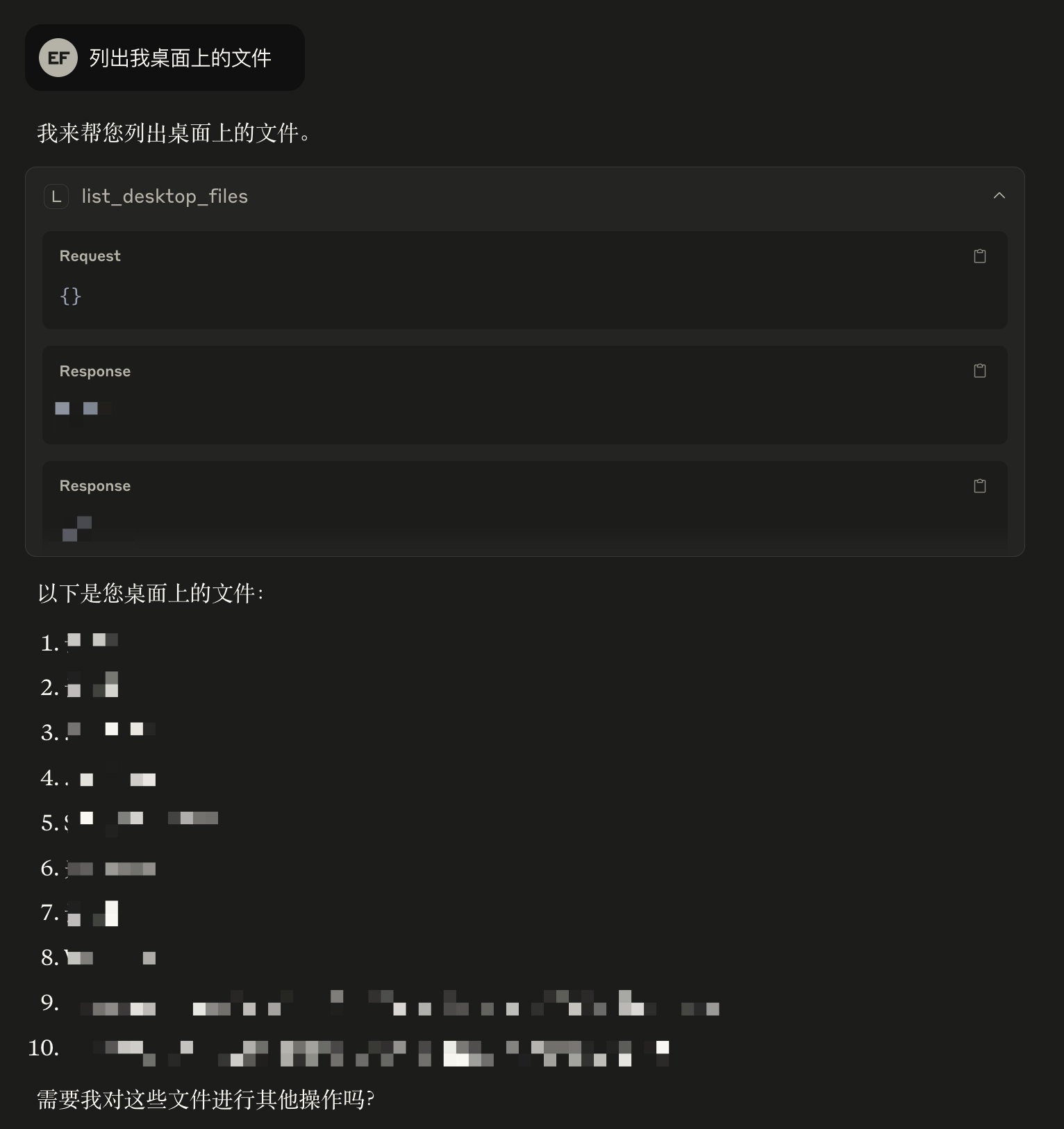
然而并不是很想给Claude打钱,求求ChatGPT Desktop赶紧更新MCP支持🙏🙏🙏。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 逸风亭!
- V me 50!
- Alipay is also ok~


相关推荐


评论
TwikooGiscus