
经典红蓝眼睛问题的思考
前两天偶然间想起一个经典的红蓝眼睛问题,这个问题最早是由Terence Tao提出的,其表述大概如下:
一个岛屿上住着一群土著,这些土著的眼睛均为红色或蓝色,其中有 $m$ 个红眼睛、 $n$ 个蓝眼睛。由于某种宗教的存在,这些土著之间遵循着一些约定俗成的规则:
土著们都不知道自己眼睛的颜色。
土著们不会通过任何方式告知其他人任何人眼睛的颜色。
如果有人知道了自己眼睛的颜色,他一定会在当天晚上自杀。
一天,有一位探险家经岛屿所属政府的批准登上了岛屿,在登岛前,为保护岛上的土著,探险家被告知「不可以给这个岛屿上的土著们带去他们以前所不知道的信息」。
登岛后,探险家发现岛上红眼睛的土著有不止一个($m\ge2$),因此,探险家心想:“每个人都知道岛上有红眼睛的人”,于是探险家对着人群大喊:“你们当中有红眼睛的人!”
“这样应该没有给土著们带去额外的信息吧”,探险家心想。
然而真的是这样吗?假设岛上的土著都十分擅长逻辑推理,考虑探险家这句话带来的后果。
相信很多朋友都听过这个问题,也很清楚答案:
第 $m$ 天晚上,$m$ 个红眼睛土著自杀,第 $m+1$ 天晚上, $n$ 个蓝眼睛 ...
部署Qwen3-32B模型并使用Cherry Studio优雅接入的一些尝试
前两天尝试在一块3090上部署了一个QwQ-32B(见下面这篇文章)。
引用本站资源,请放心访问
在消费级显卡上部署QwQ-32B模型
逸风亭博客
不过这个模型是一个推理模型(Reasoning model),它面对任何问题都会“陷入沉思”,思考过后之后才给出回答,对于某些需要快速响应但比较简单的任务而言就有点令人不耐烦了,因此,后来我又重新尝试了其他的模型,例如Qwen3-32B,这个模型则是个混合推理模型(Hybrid reasoning model),也就是说这个模型存在两种模式:思考模型与非思考模式,可针对复杂问题启用多步逻辑推理,简单任务则快速响应。
模型部署这部分总体与上面那篇文章中部署QwQ的过程类似,使用llama_server进行部署,不过为了与Cherry Studio良好适配,我还进行了一些调整。
首先是到处乱抄糊了一个jinja模板,命名为了my-templa ...

在消费级显卡上部署QwQ-32B模型
Qwen在今年3月份的时候发布了号称能媲美DeepSeek-R1-671B的32B模型:QwQ(这名字卖萌是故意的,还是不小心?)
32B模型如果做一个4bit量化的话,大约只需要占16G的显存,这样的话,一块24G显存的消费级显卡(如NVIDIA GeForce RTX 3090)也能把这个模型部署起来。拥有一个本地部署的性能匹配满血DeepSeek-R1的模型岂不美哉?于是,我紧锣密鼓地一顿部署,很快便搞定了。
下载模型模型的官方链接位于Qwen/QwQ-32B,不过我这里选择了另一个HuggingFace 上的由bartowski提供的 该模型的 llama.cpp/ggml 格式量化版仓库:bartowski/Qwen_QwQ-32B-GGUF。
找到文件:Qwen_QwQ-32B-IQ4_XS.gguf,用wget下到本地即可。
安装 llama.cpp这是一个用cpp写的大模型推理框架,链接如下:
引用站外地址,不保证站点的可用性和安全性
llam ...

动手实现一个医学问答大模型(浅尝检索增强生成方法:RAG)
前情提要 & 动机前段时间忙里偷闲和女朋友一起去了趟云南(你可以查看相册),在出发之前,由于怕女朋友高反,遂问了一圈各种AI应该带什么药、做什么准备措施,以及高反的主要症状等。在做足了功课后,职业病又犯了:我能不能自己搞个大模型小模型,让它具备专业的医学知识,以使得用户提问时,其能从专业的角度给予回答?
说干就干,由于需要一定的实用性,就不考虑 7b 以下的模型了,但7b的模型我的垃圾显卡又训不动,怎么办呢?于是我想起了曾经听说过的一种技术:检索增强生成(Retrieval Augmented Generation, RAG),这种方法不需要训练模型,直接用预训练好的模型即可。
RAG是什么?
检索增强生成 (英语:Retrieval-augmented generation, RAG ) 是赋予生成式人工智能模型资讯检索能力的技术。检索增强生成最佳化大型语言模型(LLM) 的交互方式,让模型根据指定的一组文件回应使用者的查询,并使用这些资讯增强模型从自身庞大的静态训练数据中提取的资讯。维基百科
回到我的需求:使大模型获得一定的医学知识。要使大模型具备一定的专业知识,最方便 ...

大语言模型训练原理与实践(七):GRPO算法
前情提要2025年1月27日,因中国 AI 初创企业 DeepSeek 发布低成本高性能模型,英伟达市值单日缩水约6000亿美元,股价暴跌约17%。
这事在圈内激起了不小的波澜,众所周知,大模型的训练过程十分消耗算力,尤其是常规的RLHF阶段使用的PPO算法,流程复杂又烧钱。比如OpenAI在训练ChatGPT时,动辄上万张A100、H100堆起来跑,而Nvidia几乎是算力的唯一供应商。
而DeepSeek团队推翻了这一现状:训练一个性能能够对标主流水平的大模型,并不需要那么多的卡(仅使用约2k张H800)。他们通过一套更高效、轻量的流程大幅简化了训练的成本与复杂度,其中最核心的改进便是引入了Group Relative Policy Optimization(GRPO)算法。那么,这个算法究竟是何方神圣?感兴趣的朋友可以直接阅读下面的原论文:
引用站外地址,不保证站点的可用性和安全性
DeepSeek-R1
$\text{ar}\ ...
大语言模型训练原理与实践(六):DPO算法
前面几篇文章已经基本实现了常规RLHF算法训练大模型的流程,从监督微调(SFT)、奖励模型训练(RM)到使用 PPO 进行强化学习(RL)优化模型行为。然而,我们同样注意到了当前用于强化学习的PPO算法有一些缺点:训练过程复杂、硬件资源消耗大,还往往训练不稳定、调参困难。
为了解决常规RLHF算法中的这些问题,研究者随后提出了DPO(Direct Preference Optimization)算法,它能够绕过RLHF算法中的奖励模型训练以及后面的强化学习训练阶段,在完成监督微调之后,直接通过人类偏好对比数据对模型进行对齐优化,相当于实现了不需要RL的RLHF。
建议有兴趣深入了解的朋友直接阅读原论文。
引用站外地址,不保证站点的可用性和安全性
Direct Preference Optimization
$\text{ar}\chi\text{iv}$
PPO算法的优化目标前面 ...
大语言模型训练原理与实践(五):RLHF
如前文所述,在经过指令监督微调后,模型已具备初步的指令对齐能力。换言之,它不再只是一个简单的“续写模型”,而能够根据我们提供的指令,生成比较“对题”的响应。为了进一步提升模型的响应质量,以对齐人类偏好,我们还需要用到基于人类反馈的强化学习(RLHF),通过奖励机制引导模型生成更加符合用户意图的回复。
本篇将结合我自己实现的 RLHF 流程,来介绍 PPO 算法在其中是如何具体应用的。
其中涉及到的代码均位于此仓库:
引用站外地址,不保证站点的可用性和安全性
tiny-llm-training
GitHub
如有实现上的误区还请指出!
为什么要做RLHF虽然模型已经能够回答地对题,但其生成行为仍受到训练语料限制,容易出现回答不符合人类偏好的问题。实际使用中,我们微调好的模型经常无法分辨问题是否得当,会毫无保留地“畅所欲言”,比如下面的prompt:
我们训练的模型若有其事地列举了一 ...
大语言模型训练原理与实践(四):Reward Model
在上一篇文章中,博主已经简单介绍了 PPO(Proximal Policy Optimization)算法的核心原理。然而,要让算法发挥效果,我们还需要一个关键模块:Reward Model(奖励模型)。这个模型负责为不同的输出生成打分,也就是我们在 PPO 优化目标中多次出现的那个 R_i。换句话说,Reward Model 就是大语言模型训练过程中的“裁判”——它不直接参与回答问题,但会评判哪个回答更符合人类的偏好,从而引导策略模型不断优化生成质量。
模型结构Reward Model 有两种主流的形式:
ORM(Outcome Reward Model):对序列整体生成一个得分。
PRM(Process Reward Model):在序列的生成过程中,分多个步骤,对每一步分别进行打分。
考虑到训练的模型比较简单,我们采用ORM的形式。
Reward Model作为一个为语言模型的生成结果打分的模型,自然需要一定的语言能力,因此通常会选择与策略网络相同架构的语言模型,作为Reward Model的backbone。但与策略网络不同的一点是,Reward Model不输出token ...
大语言模型训练原理与实践(三):PPO算法
在大语言模型的训练流程中,通常会先经过预训练和监督微调,经过这两个步骤后,模型已经能够理解语言结构,也能掌握基本的知识和指令执行能力,但你可能会发现,模型有时候仍会胡说八道、答非所问——这是由于监督微调出来的模型还不够聪明,它只是单纯能模仿人类已经写好的答案,但并不明白什么样的回答是「好的」(更符合人类偏好)。说白了,模型在监督微调阶段学的是「怎么答」,但没学会「怎么才能答得好」。
为了进一步提升模型输出的质量和对齐程度,研究者引入了基于人类反馈的强化学习(RLHF)。通过奖励模型对不同响应进行偏好打分,再利用强化学习算法对语言模型进行微调,使其在生成文本时更加贴合人类价值与偏好。其中,PPO(Proximal Policy Optimization) 是 RLHF 阶段最常用的优化算法,也是在 InstructGPT 和 ChatGPT 等模型中取得显著效果的关键技术。
本文将先从这个PPO算法入手,拆解此算法的核心理论。
策略梯度算法PPO算法是一种On-Policy的策略梯度算法,关于策略梯度,我在之前的一篇文章中曾提到过其核心公式的推导:
\nabla_\theta J(\ ...
大语言模型训练原理与实践(二):监督微调(SFT)
在前两篇文章中,博主已经简单介绍了大语言模型的预训练阶段,以及如何通过BPE(Byte Pair Encoding)算法将自然语言高效地转化为离散的子词单元,从而降低词表规模、提高模型泛化能力。
我们已经知道,在大规模语料数据上进行的预训练使模型具备了广泛的语言知识,但它学到的仅仅是“如何预测下一个词”的通用能力,距离解决特定任务(如问答、摘要、对话)还有相当的差距。
而监督微调正是让大语言模型从通用语言能力升级到任务导向能力的必经之路。换言之,SFT让模型不仅仅局限于能够把话写通顺,还能写的对题。
另外,博主基于一款参数量约为 2.13B 的迷你大语言模型,完成了其微调流程的简要复现。相关代码已开源,详见下面链接。
通过合理配置训练参数,并结合 LoRA(Low-Rank Adaptation),整个微调训练流程可在一块消费级显卡(博主使用的是 RTX 3090 Ti)上顺利完成。
引用站外地址,不保证站点的可用性和安全性
tiny-llm-training
...
大语言模型训练原理与实践(一): BPE分词算法
上一篇文章中,我们已经了解了大语言模型通过在海量自然语言语料上学习预测下一个 token,以此建立语言理解能力,这一过程也就是所谓的预训练。那么问题随之而来:我们经常提到的token究竟是什么?它与文本、词汇之间有着怎样的关系与区别?
为了解决这个问题,我们需要从文本如何被编码成模型可读的序列说起。
早期的编码方案字符级编码以英文为例,在早期的文本编码方案中,每个字符都被单独视为一个token,这也被称为字符级编码。例如,对于句子:”hello world!”,它的token序列(尚未映射为数字)为:['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!']。
这种编码方式的优点十分明显:实现简单、通用性(可扩展性)强,词表较小,可以处理几乎所有语言中的所有字符,不会存在OOV(Out-Of- Vocabulary)问题。然而,它也存在 ...
大语言模型训练原理与实践(零):预训练
前言(吐槽)自从大语言模型横空出世,各行业的从业者都仿佛开了挂似的,科研、工作效率那是咔咔上涨,唯独我这个正儿八经的AI在读博士生,现在却感觉自己成了个小丑🤡:眼睁睁看着LLM在世界舞台上风生水起,自己训练的人工智能模型一个个都跟人工智障似的,别说去现实环境投入使用了,连外行审稿人都忽悠不过去;至于这💩上雕花的缝合怪科研,也是憋不出个屁黔驴技穷了。最绝望的是,当我试图投身LLM的怀抱时,不好意思,显存都不够训练个demo。
在有点腻了这种闭门造车的行为以后,吐槽归吐槽,作为一个实干型的炼丹师,光把大模型用于应用、推理是远远不够的,还得弄明白它的训练原理。毕竟,只有了解了这些,才不至于在调参和部署中沦为“黑箱”工具的操作者,也意味着能更有针对性地优化数据处理流程、设计更有效的模型结构。换句话说,搞清楚训练原理,是从“用大模型”到“造大模型”的分水岭。
既然如此,接下来就该跳出“只会用API”的舒适区,真正去了解一下大模型训练过程中的三块核心拼图:预训练、SFT、RLHF 。
在开始之前,先叠几层甲:
由于笔者没有充足的算力去支持具有实用价值的大模型的训练、微调工作,本系列文章只是尽 ...
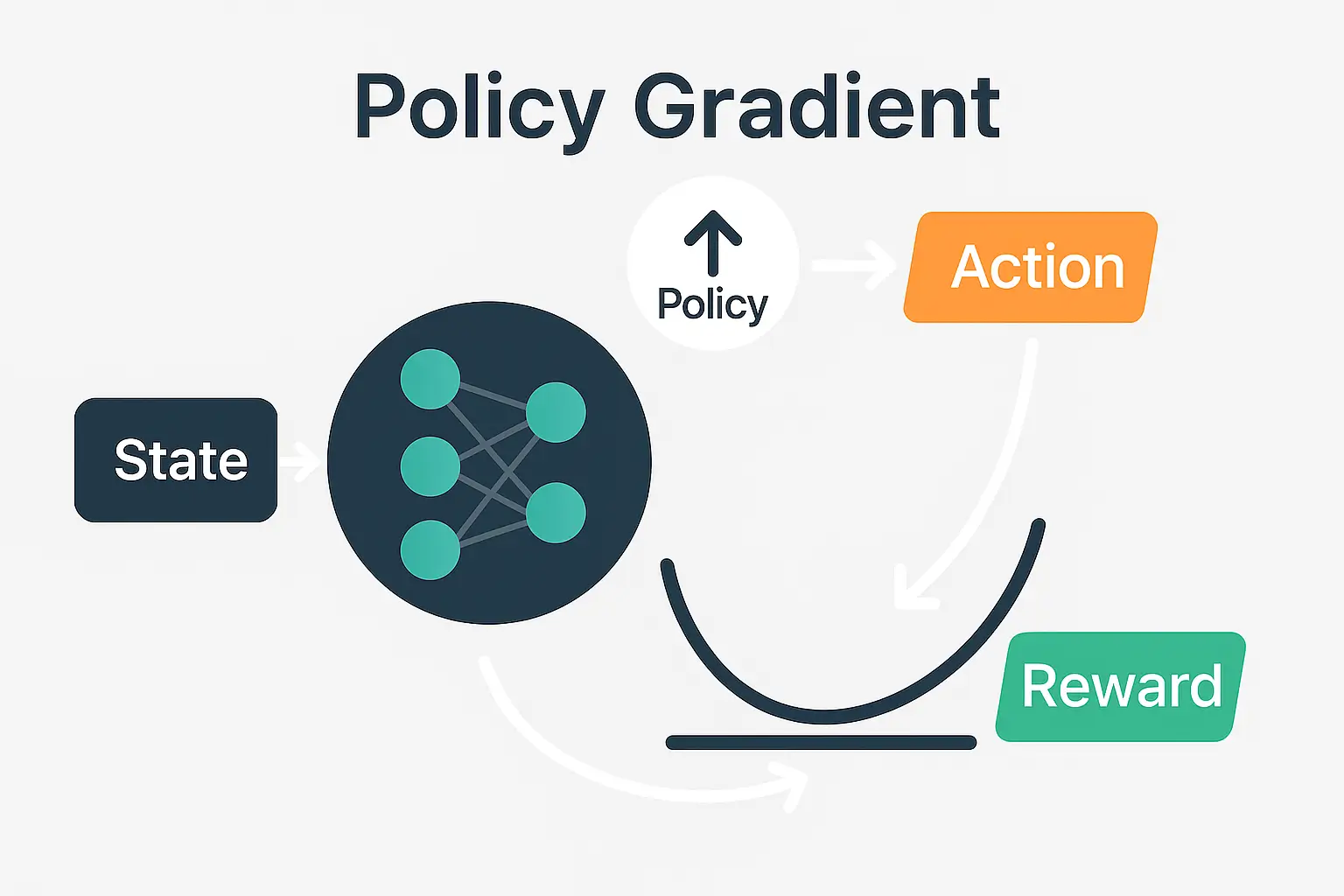
策略梯度算法中梯度公式的推导
最近学习强化学习的策略梯度算法时,遇到其中策略梯度的计算部分,一些推导的细节在我所学习的视频中被一句话带过了,而这些推导过程本该十分重要,故在本文中简单整理一下。
首先表述几个基本的符号:
S 是全体状态的集合,A 是全体动作的集合。
\pi_\theta(*\mid s_t) 表示以 \theta 为参数、在 t 时间步的状态 s_t 下的动作策略,是一个概率分布。\theta 即是本算法优化的参数。
R_t 表示时间步 t 的即时奖励。
U_t=\sum_{i=t}^n\gamma^{i-t}R_i 表示从时间步 t 开始的累计回报。
Q(s_t,a_t)=\mathbb{E}[U_t\mid s=s_t,a=a_t] 表示在状态 s_t 时采取动作 a_t 时能获得的累计回报 U_t 的期望值。
V_{\pi_\theta}(s_t)=\mathbb{E}_{a_t\sim\pi_\theta(*\mid s_t)}[Q(s_t,a_t)] 表示在状态 s_t 下,使用动作策略 \pi_\theta 时,Q 函数的期望值。
J(\theta)=\mathbb{E}_{s\in ...

MCP服务编写实践
动机前文曾提到可以使用MCPM管理各种现成的MCP服务以使得大语言模型接入许多现成工具,那么自然会想要自己写一个适合自身需求的工具来让大模型调用,本文就来简单记录一下这个过程。
关于MCP服务的编写,GitHub上已经有了现成的仓库了:
引用站外地址,不保证站点的可用性和安全性
modelcontextprotocol
GitHub
作为一名练习时长两个两年半的Python练习生,我选择了其中的Python SDK。
配置环境这个Python SDK支持的Python版本为:>=3.10,并且最好使用uv管理环境。
因此先安装uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv安装完成后,初始化项目目录:
uv init mcp_server
该操作会生成一些配置文件,以及一个虚拟环境,检查.python-version以 ...

MCPM:让LLM调用你电脑上的一切工具
前言自从大语言模型(LLM)诞生以来,至今已有两年多的发展时间。如今市面上的各类 LLM 模型层出不穷,功能趋于同质化,用户的选择越来越多。然而,作为一名 LLM 重度用户,显然不满足于仅在聊天窗口中进行简单的对话式交互——更希望将 LLM 作为智能助手,融入到本地工具链中,提升工作效率并拓展应用边界。这些工具并不局限于诸如 VS Code、JetBrains IDE 等开发环境(这些IDE自身已经提供各种LLM的插件,以辅助代码编写),还包括终端命令行、文件管理器、数据库客户端、甚至是操作系统本身提供的原生命令与服务。将 LLM 与本地工具链深度集成,不仅能够实现自然语言驱动的自动化操作,还可以显著扩展模型的执行能力与实用性。为了实现这一目标,开放式的模型上下文协议(Model Context Protocol, MCP),为我们提供了一个标准化、可扩展的集成方案。
但如果为各种大模型、各种软件分别配置对应的MCP,则会非常的麻烦。很巧的是前两天,一位我关注的UP:严伯钧,发布了一个视频,提到他们团队开发了一个用于一站式管理各种软件MCP的开源软件:MCPM,我一看,欸🤓👆,这不 ...
Python随机数的背后:MT19937算法之——实战演练
本文是一道MT19937随机数预测的实战题,这道题是我2019年第一次参加Hackergame时遇到的,题目链接如下:
引用站外地址,不保证站点的可用性和安全性
大整数分解锦标赛
GitHub
当时我还是一个只会一点点Python的计算机小白,只做了几道最简单的题就结束了自己的赛程。自然,这道题我当时根本就没看,赛后看题解的计划也被我咕咕咕了,一直到最近才自己做了一遍。
题目分析题目服务端的源代码位于这个文件:factorme.py
在本地模拟题目环境:
socat TCP-LISTEN:9999,fork EXEC:"python factorme.py"
我们可以在1分钟之内(signal.alarm(60))与服务器进行两种交互:
发送H,服务端会发给我们一段帮助文本
发送B,调用下面函数:
def begin():
for i in range(10, 10 ...
Python随机数的背后:MT19937算法之——小试牛刀
本文为几道MT19937预测题的题解。这些题都非常基础+典型,十分适合入门。
本文用到的mt19937来自此gist。
第一题#!/usr/bin/env python3
import random
for _ in range(624):
print(random.getrandbits(32))
if input() == str(random.random())
print(open("flag").read())
非常简单的预测,给了连续624个32bit随机数,只需把它们依次输入预测器,就能恢复出完整的内部状态。
import tqdm
from mt19937 import MT19937Predictor
from pwn import remote
r = remote(HOST, PORT)
predictor = MT19937Predictor()
for _ in tqdm.tqdm(range(624)):
data = int(r.recvline().decode())
predictor.setrand_int32 ...
Python随机数的背后:MT19937算法之——状态恢复
前一篇文章中,我们已经逆向了Python中的随机算法,在本文中,我们将在前文的基础上对MT19937的状态数组进行恢复,从而达到预测随机数的效果。
根据前文的分析,我们知道一旦还原了随机数发生器完整的内部状态,就相当于复刻了一个完全相同的随机数发生器,也就能预测后面的随机数了,并且我们还知道,每次提取随机数时,是取出某个下标位置的状态向量并将其进行tempering运算,最终输出。
def extract_number(self):
if self._mti >= self.N:
for i in range(self.N):
self.twist(i)
self._mti = 0
y = self._mt[self._mti]
y = self.tempering(y)
self._mti += 1
return _int32(y)
当下标运转一整轮(即624次)时,我们相当于把每个状态向量都提取了一次,这说明连续提取出来的624个32bit随机数是与624个内部状态向量一一对应的 ...
Python随机数的背后:MT19937算法之——算法逆向
前一篇文章分析了Python中随机算法的实现细节,本文就来对其进行逆向。
由前文所述,MT19937提取随机数可分为两部分:twist 、tempering
def extract_number(self):
if self._mti >= self.N:
for i in range(self.N):
self.twist(i)
self._mti = 0
y = self._mt[self._mti]
y = self.tempering(y)
self._mti += 1
return _int32(y)
那么,其逆向过程就先从termpering操作开始。
逆向 temperingdef tempering(y):
y ^= (y >> 11)
y ^= (y << 7) & 0x9d2c5680
y ^= (y << 15) & 0xefc60000
y ^= (y >> 18)
return ...
Python随机数的背后:MT19937算法之——算法分析
前言先前在做各种CTF时,总会遇到一些预测Python随机数的题,虽然知道伪随机数生成器都可以在一定条件下被预测,但由于不懂背后的原理,每每遇到此类题型就折戟于此。最近痛定思痛趁着兴趣练习了几道相关题型,在过程中把Python的伪随机数算法逆向了一下,觉得颇有收获,因此写几篇网上相关内容早已烂大街的博客记录一下。
笔者的代码公开于此gist。
本文主要分析一下Python使用的伪随机数算法:MT19937
梅森旋转算法介绍引用维基百科:
The Mersenne Twister is a general-purpose pseudorandom number generator (PRNG) developed in 1997 by Makoto Matsumoto) (松本 眞) and Takuji Nishimura (西村 拓士). Its name derives from the choice of a Mersenne prime as its period length.
The Mersenne Twister was designed specifically t ...